via https://moz.com/blog/measuring-ai-search-like-seo
多年来,SEO从业者有一套熟悉的追踪进度的方法。即便归因变得混乱,这套基本模型也足够让团队规划、衡量并为自己的工作辩护。但AI搜索不同,因为其价值并不总是以点击甚至排名来体现。
一个品牌可能被推荐,却未被明确引用;而当大多数活动并不产生直接点击时,转化追踪就变得困难。
在这次AMA(问我任何事)中,Tom Capper 解释了为什么AI搜索需要一种新的思维模式,以及SEO从业者实际上应该追踪、屏蔽和优化哪些指标。
第1部分:AI搜索的工作原理
1. SEO从业者对AI的认知与AI搜索实际运作之间最大的差距是什么?
最大的差距在于思维模式。
AI并非突然取代了词法搜索;后者在ChatGPT出现之前很久就已经在衰落。因此,许多SEO的假设在AI搜索兴起之前就已经过时了。
这并不意味着AI搜索与SEO完全无关。当人们说“它仍然是SEO”时,他们是在暗示有些策略在两者中都适用。这没错,但你需要改变对这些策略的组合方式、优先级以及思考角度。
SEO从业者仍然是最适合主导这项工作的人,因为我们早已懂得如何优化在搜索环境中的可见度。
但我们不能把AI回答当作传统排名来对待,也不能认为旧的策略手册无需调整就能直接套用。
AI搜索要求SEO从业者更新他们用来理解可见度的底层模型,而不仅仅是给同样的策略重新命名。
2. 依据搜索(grounding searches)是如何运作的?品牌如何影响它们?
依据搜索发生在AI系统决定需要外部信息来回答某个提示词时。
例如,如果你让它写一首关于蝴蝶的诗,它会使用内部的训练数据(可能已经过时多年)在模型内生成回答。
但如果你问它“Tom Capper是谁,他最近在做什么”,它几乎肯定会在回答之前在后台多次运行谷歌搜索。
这些后台搜索对于提示词追踪和提示词研究很有价值。根据所用工具,你可以在浏览器控制台中查看它们,谷歌也在其扇出视图(fan-out view)中提到了这一点。
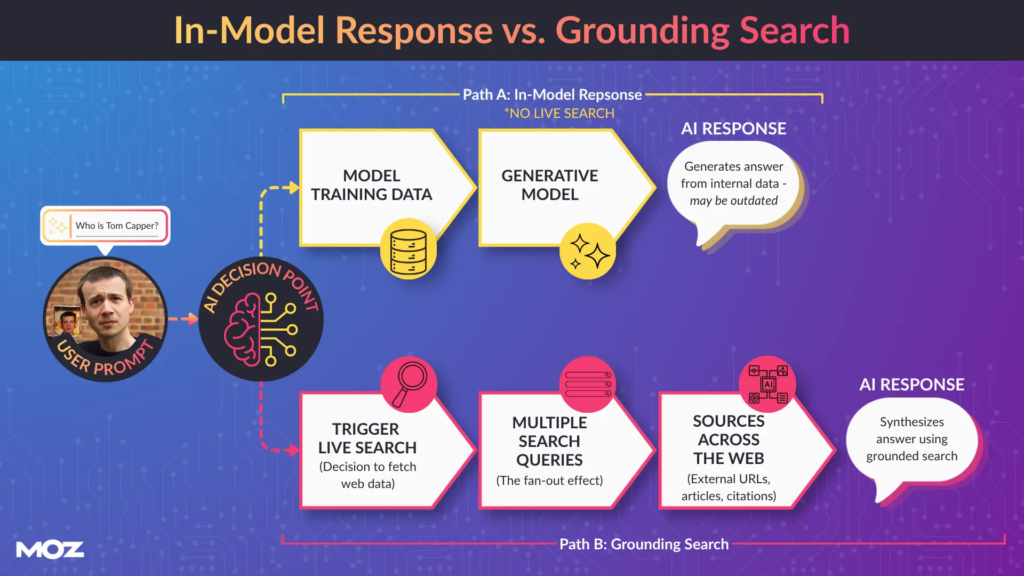
这些工具运行的搜索可能有些奇怪,我不建议针对这些确切的查询进行排名追踪。但它们显示了可见度运作方式的一个重要转变。
过去,SEO的问题是:“如何让我的网站出现在这个查询结果中?”
现在的问题是:“如何确保AI系统所使用的来源能正确描述我的品牌?”
系统并不关心信息来自你的网站还是别人的网站。依据搜索会从最佳答案所在的地方抓取信息,包括你的网站和外部来源。
因此,与过去很长一段时间(甚至可能是有史以来)的SEO相比,现在对外部工作的重视程度要高得多。事实上,我曾称之为“数字公关”登上了大雅之堂。”**
3. 针对AI搜索的提示词研究与针对传统搜索的长尾关键词研究有何不同?
提示词研究比传统关键词研究更加“长尾”,这使得精确的提示词搜索量变得不那么有用。
你可以从点击流数据等来源获取提示词的搜索量,但这并不意味着它拥有与关键词搜索量同等的价值。
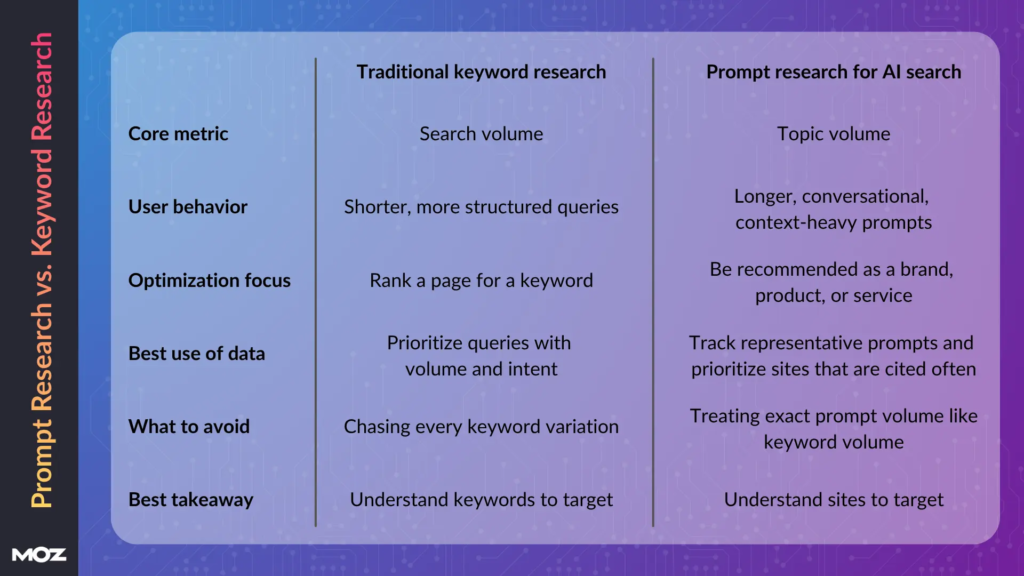
大多数提示词更长、更具对话性,并且深受上下文影响。高搜索量的提示词往往只是对话中的填充语,比如“谢谢”——实际上没有人会去针对这类词做优化,因为它们的含义完全取决于所处的对话语境。
对于传统SEO,搜索量帮助你决定优先优化哪些查询。而对于AI搜索,更好的做法是:
- 识别感兴趣的主题
- 追踪代表这些主题的提示词
- 了解谁被引用,以及你的品牌如何呈现
- 监测围绕该主题的回复随时间的变化
查询扇出(query fan-out)方法论正指向这个方向。它不问“有多少人搜索了某个具体短语”,而是问“围绕某个主题聚集了哪些话题和意图”,并追踪引文的变化。
有用的信号存在于主题层面,而非单个提示词层面——这就是为什么提示词研究不应照搬旧的关键词模式。
第2部分:爬虫策略与抓取访问
4. 品牌应如何思考自己的爬虫屏蔽策略?
品牌在决定屏蔽哪些爬虫之前,需要先区分训练爬虫和依据爬虫。
训练爬虫服务于底层模型。在许多情况下,屏蔽它们可能在数年之内都不会影响回复内容,因为大型模型的重新训练或替换速度很慢。
依据爬虫则不同。它们支持实时检索、网络搜索以及对用户查询的实时响应。如果你屏蔽它们,当AI系统需要最新信息时,可能会无法访问你的内容。
一些发布商(如这项研究中提到的那些)有充分的理由采取更激进的屏蔽策略,尤其是在与AI公司谈判或保护以流量为核心的商业模式时。但对于大多数品牌而言,保持依据爬虫开放是合理的。
这也会影响你的站外策略。第三方报道只有在LLM能够访问时才能帮助AI可见度。如果这些网站屏蔽了依据爬虫,那么这些报道可能不会出现在实时回复中。因此,请检查你的目标网站是否屏蔽了依据爬虫。
以下是可操作的实用方法:
- 了解你正在屏蔽哪些用户代理(训练爬虫 vs 依据爬虫)
- 避免默认屏蔽依据爬虫;如有疑虑,就不要屏蔽
- 如果你决定屏蔽依据爬虫,请确保有充分的业务理由
- 花时间了解屏蔽对你自己的网站以及提及你的第三方网站会产生什么影响
5. LLMs.txt 是否已经名存实亡,还是说存在被忽视的合理用途?
我曾认为 LLMs.txt 是江湖骗术,但后来我发现 Anthropic 正在要求使用它。在AI SEO领域存在一种我们以往在谷歌主导的世界里不熟悉的奇特循环——有时候,一个搜索引擎眼中的“骗术”可能成为另一个引擎的现实。
我无法说明 Anthropic 实际如何使用这些数据。我只能说,如果你的AI SEO策略是以谷歌为中心——我认为在绝大多数情况下本应如此——那么你的 LLMs.txt 文件就毫无作用。
话虽如此,实现这个文件并不费力,所以你可能会说:何乐而不为呢?
Limy 对5.15亿次LLM爬虫流量事件的分析发现,几乎没有证据表明主流AI爬虫依赖该文件,但确实发现了代理式(agentic)使用的迹象。
目前,我不会在这方面花太多时间。还有更有价值的领域需要优先关注,尤其是了解AI系统使用哪些来源来描述你的品牌。不过,如果你能在十分钟内顺手放上一个 LLMs.txt 文件,那就去做吧。
第3部分:衡量正确的指标
6. SEO从业者在提示词追踪方面犯的最大错误是什么?
提示词追踪最大的错误就是把它当作排名追踪。
如果你看着某个AI回复说:“哦,显示的第一个URL是我的,所以我排名第一,这就是成功。”——那你衡量的东西就错了。
AI搜索不会像传统搜索那样传递流量。它有价值,但这种价值与传统的不同类型。
点击率不再是SEO从业者习惯的样子,而提示词追踪也不应仅凭链接、点击或URL位置来评判。
更好的衡量指标更接近于你评估其他营销渠道的方式:
- 你的品牌是否可见?
- 你是否参与了对话?
- 你是否被推荐?
- 你是否与正确的主题相关联?
- 权威来源是否准确描述了你?
即使你的网站未被引用,一次推荐仍然可以算作胜利。
例如,如果用户询问最适合他们需求的智能手机,AI回复推荐了三星并引用了 PCMag,我不会认为这对三星来说是失败,因为三星仍然获得了推荐。引用很重要,但不是唯一重要的。
这在归因上堪称噩梦,但它反映了目前AI可见度的运作方式。我们无法像十年前那样拼凑出精确的贯穿归因。因此,提示词追踪必须在传统SEO指标之外,同时衡量可见度、推荐和品牌关联。
你可以轻松构建提示词列表,并使用 Moz AI Visibility 工具来追踪你的提示词。Crystal Carter 创建了一份详细指南,手把手教你操作流程。
(最后机会:MozCon NYC 门票可享六折优惠)
第4部分:站外策略与品牌叙事
7. 旧内容被引用的频率会降低吗?重写内容能解决这个问题吗?
你可以针对自己的网站回答这个问题,但答案会因网站而异。
首先查看以下内容:
- 在品牌可见度工具中,你所追踪的提示词对应的引用情况
- 日志分析,查看AI爬虫访问了哪些页面
- 围绕你的品牌和主题的依据查询所排名的页面
如果某些页面的引用量下降,可能是因为它们不再排名于依据查询中。更新这些内容有助于让它们重新出现在AI系统用于回复的搜索结果中。
然而,仅仅就同一主题创建新内容并不能解决问题。优先要做的,是识别AI平台在相关主题上信任哪些来源。
现代SEO要求你跳出自己的网站去思考。这是过去五年中最大的变化。
虽然内容更新很重要,但更大的机会在于影响那些已经为你的品牌或品类出现的第三方网站。
影响这些外部来源,往往比改写自己的文章更能提升可见度。
搜索的未来走向
8. 五年后,我们所熟知的谷歌搜索还会存在吗?
我预计会是演进,而非革命。
五年后,谷歌搜索结果页(SERP)的截图可能会看起来大不相同,但我不认为它会为所有查询都变成“AI模式”。谷歌更可能走向一种混合体验——搜索结果页面会根据搜索意图发生更剧烈的变化。
其实今天我们已经在见证这一点。本地查询、产品查询和信息类查询的结果页面可能看起来完全不同,而这种趋势很可能会持续下去。
我也不认为谷歌会在短期内停止发送外链流量。这种事最终可能发生,但会带来变现难题,因为谷歌的商业模式仍然建立在发送流量的基础之上。
谷歌自己的AI功能文档仍然将AI概览和AI模式定位为“展示链接”的体验,这支持了混合SERP的观点,而不是用一个AI答案取代所有结果。
未来这种情况会改变吗?理论上,有可能。
代理式电商(agentic e-commerce)可能会取代其中一部分。但这尚未被验证,也并不适用于所有类型的业务。五年是很长的时间,但还不足以让谷歌从头重建其商业模式。
Web Guide 是目前值得关注的有趣实验之一,因为它指向了一个混合型的未来。
9. 当前对于AI可见度来说,最被低估的技术操作是什么?
我认为日志分析(log analysis)是目前最被低估的AI可见度技术操作,尤其是对规模较大的团队而言。
Search Console 的效果越来越差,而且大多数AI平台并没有直接等同于 Search Console 的工具。这使得日志文件成为了解AI系统在访问什么内容的最佳途径之一。
在之前的AMA中,Jamie Indigo 解释道:
“AI爬虫可能具有攻击性且资源消耗巨大。它们会爬取公开的开发环境区域,而‘依赖隐藏来保障安全’是行不通的。日志文件能告诉你实际发生了什么,而不是仪表盘所假设的情况。”
下图是一个示例,展示可能的样子(此处保留图片说明)。
日志分析可以揭示:
- 哪些AI爬虫在抓取网站
- 它们请求了哪些页面
- 它们在哪些地方遇到了访问或性能问题
- 重要页面是否被访问到
- 不同平台的抓取行为有何差异
它并不能取代需求侧工具,因为你仍然需要像 Moz AI Visibility 这样的工具来了解AI的呈现情况。
然而,AI搜索所需的数据与你在传统SEO分析中使用的数据并不相同。
(在 MozCon NYC 见到 Tom Capper,门票六折优惠)
总结:别再像衡量SEO那样衡量AI搜索了
要在搜索的下一个阶段取得成功,SEO从业者必须重新思考如何衡量可见度,并针对这些新的搜索界面进行优化。
有些策略仍有重叠,但人们发现、评估并依据信息采取行动的方式正在发生变化。