via https://www.chris-green.net/post/diving-into-chatgpt-5-s-web-search-function
ChatGPT 5现已发布,Profound团队的Josh迅速跟进,帮助深入解析该搜索服务的运作机制。
看到Charlie分享了GPT5的潜在系统提示(我说“潜在”,是因为仍不确定能否获得极其精准的信息),我决定仔细研究对话事件流中的情况——它与ChatGPT 4.1有何不同?这对我们的工作方式会产生影响吗?
关键问题/观察
目前尚处早期阶段,仍需大量研究,但初步发现如下:
若想真正理解我们需要在哪些搜索引擎中保持可见性,针对SonicBerry内部搜索服务引文来源的研究比以往更为重要。
SonicBerry是单纯聚合结果,还是在提交给GPT5前会对结果重新排序?若存在重排序机制,采用哪些信号指标?这点至关重要。
初步测试中尚未发现扇出(fan-out)案例,但这不表示该现象不存在或不可见。
针对以下场景的分类器将极大帮助我们理解搜索实现方式(查询次数、分层搜索等):
a) 何时需要搜索
b) 搜索复杂度层级
开展大规模研究并追踪随时间推移的变化,这对AI搜索领域极具实践意义。
SonicBerry付费版与免费版在使用时是否存在质量或完整性的差异?抑或仅用于追踪目的?这种差异源于供应商接入方式(如Google/Bing API配额)还是索引更新频率?免费用户是否会因调用低级别API而获取陈旧结果?
若对搜索结果进行更多聚类清洗(配备备用方案),可能会提升引文准确率并减少错误链接。是否存在更完善的防护机制来规避“危险”或“法律敏感”内容被呈现?或许这些措施正在协同发挥作用。
何时/为何需要启用备用方案?触发因素及其影响是什么?
搜索功能在多大程度上依赖元数据而非直接抓取页面内容?推测精准的元数据依然关键,且无需JavaScript即可抓取内容的能力仍然重要,但这需要进一步验证。
搜索功能实际被调用的频率如何?
搜索调用数据
本节内容仍在完善中,感谢各方持续提供信息。当前数据受关键词样本偏差影响较大,但积累多元化账户数据仍具重要价值。
若您愿意提供协助,欢迎联系我们——期待在此呈现更丰富的数据!
SE Ranking 数据
SE Ranking团队基于其AI追踪系统提供了相关数据支持。
在10万个关键词样本中,15.77%的查询返回了网络搜索引文来源。但整体数据可能掩盖细节,以下是细分领域数据及平均查询长度分析:
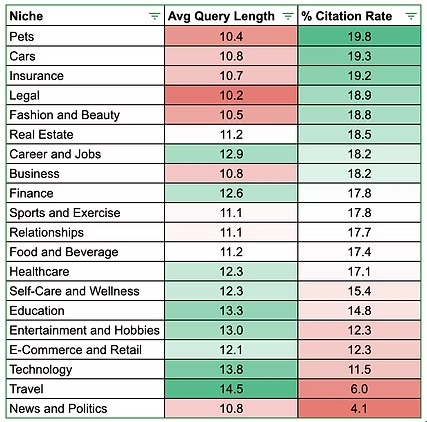
几项值得关注的发现:
- 宠物类查询的引文率接近20%
- 汽车与保险类查询紧随其后,分列第二、三位
- 旅游、新闻与政治类查询引文率极低(<10%)
- 引文率似乎与查询词长度存在相关性*(皮尔逊相关系数达0.52)
*此处词长可能代表查询复杂程度
这与先前数据(见下文)存在差异,但可能与关键词样本的相似性有关。在进行数据分段与公平对比前,我们需将此现象置于约10-30%的引文率区间内考量
Chris Long 的数据研究
Chris Long测试了近8700个查询词(虽多为高意向/交易类词汇),发现其中31%的查询触发了web.search()功能——这与我对2000条查询子集的测试结果基本吻合。更多细节可参阅其LinkedIn文章,以下是他提供的关键摘要:
- 搜索总次数:2,648次
- 触发搜索比例:31%
- 平均搜索次数:2.17次
- 平均查询词长度:5.48个单词
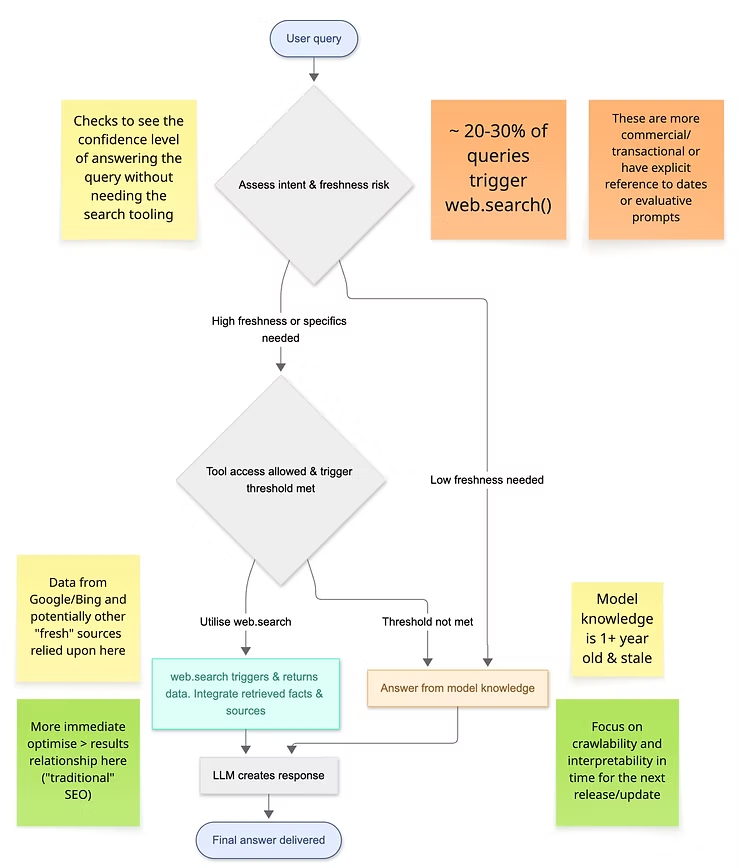
web.search() 运行机制解析
第二代网络搜索流程(Web Search Flow V2)
这对SEO及日常实践有何影响?搜索功能的触发时机(及其未触发的情况)将直接影响我们优化ChatGPT内容的方向。
V2版本的提出旨在更清晰地描述可操作的优化步骤,并呈现更多调研成果的输出路径。
流程V1(保留旧版以供参考)
以下为(旧版)流程总结及参考说明:
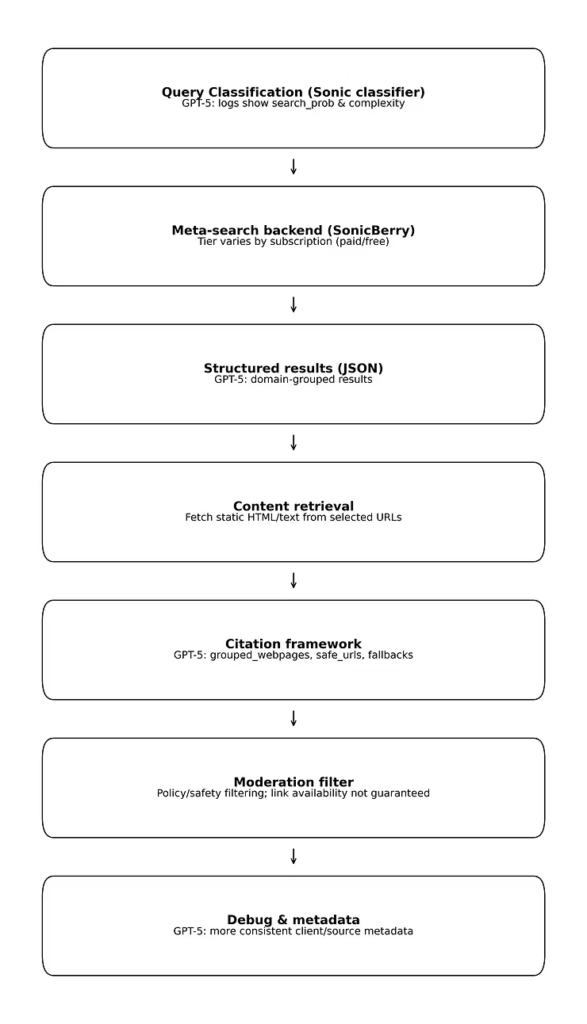
各部分详细说明附后
1. 搜索触发决策
- 由Sonic分类器(如sonic_classifier_3cls_ev3)判定是否需要执行搜索
- 示例:当查询”伦敦天气如何?”时,搜索概率值(search_prob)=0.91 → 触发搜索
- GPT-5潜在变化:日志中可能更持续显示分类器详情(搜索复杂度、复杂搜索概率等)
2. OpenAI元搜索后端(SonicBerry)
- SonicBerry作为ChatGPT与网络间的元搜索”中间层”已有记录——它不仅是Google或Bing,也不仅是二者的简单组合
- 聚合来自多个授权/公开来源的结果
- 示例:付费用户显示模型ID=current_sonicberry_paid,免费用户显示current_sonicberry_unpaid_oai
- 关键问题:付费状态是否影响结果质量?需进一步验证
- 说明:此分层机制取决于订阅类型,并非GPT-5特有变化
- 注:当被问及时,ChatGPT5暗示可能包含Google、Bing及其他服务——但这可能仅为推测
3. 结构化结果处理
- 返回包含URL、标题、摘要、来源归属(有时含发布日期)的JSON格式结果
- GPT-5似乎会使用search_result_groups进行结果分组(如将所有TechRadar链接归组)
4. 内容获取机制
- 必要时通过web.open_url打开URL读取全文
- 示例:获取”https://www.bbc.com/news/…”完整HTML内容
5. 引用框架
- 存在关于内容引用方式可能改进的线索:
- 将论述链接至对应信源
- GPT-5使用grouped_webpages、safe_urls、fallback_items等参数,并将引用映射至特定文本段
- 示例:”Wix推出AI Visibility Overview功能¹” → ¹TechRadar
6. 内容审核机制
- 引用规范可能更加严格:这里的”安全”是否指”准确”或”避免OpenAI陷入法律纠纷”?
- 是否存在URL显示前的全面检查机制?safe_urls参数暗示此可能性
- GPT-5的审核事件似乎已被记录
7. 调试与元数据
- debug_sonic_thread_id用于关联对话中的所有搜索步骤
- GPT-5显示更多客户端元数据(如search_source=”composer_auto”)