原文地址:https://www.mariehaynes.com/what-if-user-satisfaction-is-the-most-important-factor-in-seo/
让我看看能否说服你!
我在视频中分享了许多内容,并在下方文章中总结了我的观点。此外,这是我上周内就此话题撰写的第二篇博客文章。关于用户数据及谷歌如何运用这些数据,更多详细信息可查阅我之前的博客文章。
排名机制包含三大组成部分
从谷歌反垄断案庭审中我们了解到,谷歌的排名流程主要涉及三大组成部分:
1.传统系统用于初始排名
2.人工智能系统(如RankBrain、DeepRank和RankEmbed BERT)对前20-30个文档进行重新排序
3.这些系统依据质量评估员的评分进行优化调整,而在我看来更重要的是基于实时用户测试结果进行调整
谷歌反垄断案庭审详细讨论了谷歌如何凭借海量用户数据获得巨大优势。在上诉中,谷歌表示不愿遵从法官要求其向竞争对手移交用户数据的裁决。他们列举了两种利用用户数据的途径:一是通过名为”粘合剂”的系统,该系统整合了Navboost来分析用户的点击与互动行为;二是在RankEmbed模型中运用用户数据。
RankEmbed模型非常精妙。它将用户的搜索查询映射至向量空间,与该查询可能相关的内容会被定位在邻近区域。该模型的优化依据两个方面:
- 质量评估员的评分。他们获得两组结果——”冻结版”谷歌搜索结果和”重新训练版”结果(即经过新一轮训练和优化的人工智能搜索算法产生的结果)。他们的评分帮助谷歌系统判断重新训练的算法是否产生了更优质的搜索结果。
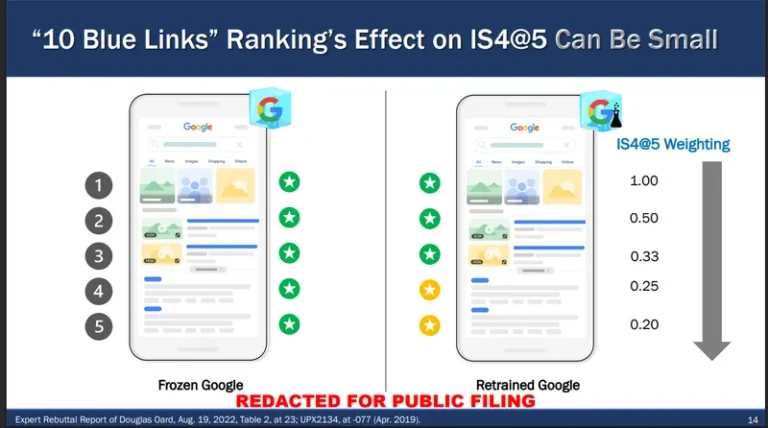
2) 真实环境下的实时实验:小部分真实搜索用户会看到来自旧算法与新训练算法的对比结果。他们的点击与互动行为有助于优化系统。
这些系统的终极目标,是持续提升搜索结果排名以满足搜索者的需求。
关于实时测试的进一步思考——用户告诉谷歌的是“有帮助的页面类型”,而非具体页面
我意识到,谷歌的实时用户测试不仅是为了收集特定页面的数据,更重要的是训练系统识别规律模式。谷歌未必通过追踪每一次用户互动来为某个具体网址排名,而是在利用这些数据教会他们的人工智能识别什么才是“有帮助的”内容。系统通过学习识别那些能满足用户意图的内容类型,进而预测你的网站是否符合这种成功模式。
他们将持续改进预测哪些内容可能更有帮助的流程。这显然远远超越了简单的向量搜索。谷歌正在不断探索理解用户意图及如何满足意图的新方法。
这对SEO意味着什么
如果你的网站能在搜索结果前几页中占据一席之地,说明你已经成功说服传统排名系统让你进入排名竞争。
进入前列后,众多人工智能系统便开始运作,预测哪些顶部结果真正最适合搜索者。随着谷歌开始在Gemini和AI模式中运用“个人化智能”,这一点变得尤为重要——我的搜索结果将根据谷歌系统认为对我有帮助的内容进行量身定制。
一旦开始理解人工智能系统如何进行搜索(主要依赖向量搜索),很容易让人想要尝试逆向工程这些系统。如果你通过深入理解向量搜索的偏好(包括使用余弦相似度等方法)进行优化,本质上是在努力让人工智能系统青睐你。但我想提醒:切忌在这方面钻得太深。
考虑到这些系统正持续优化,以不断提供最令搜索者满意的结果,单纯让人工智能青睐远不及真正成为最有帮助的结果来得重要。 我认为,除非你的内容确实属于用户最终觉得比其他选择更有帮助的类型,否则针对向量搜索进行优化可能弊大于利。因为若不如此,你很可能会在无意中“训练”人工智能系统不再偏爱你

我的建议
我的建议是:宽松地进行向量搜索优化。我指的是不要过度纠结于关键词和余弦相似度,而应致力于理解你的受众想要什么,并确保你的页面能满足他们的具体需求。
那么,利用对谷歌“查询扩展”的了解是否有帮助呢?在某种程度上是的,因为了解用户围绕某个查询通常会有什么问题是有益的。但是,我认为我之前的担忧在这里同样适用。如果你在试图满足查询扩展的人工智能系统看来表现优异,但用户往往不认同,或者与竞争对手相比,你缺乏其他与“有帮助性”相关的特质,你反而可能“训练”谷歌的系统减少对你的偏爱。
善用标题——不是给人工智能系统看,而是帮助你的读者理解他们寻找的内容就在你的页面上。
研究那些针对本应导向你页面的查询、却被谷歌排名靠前的页面,并真诚地问自己:搜索者觉得这些页面的哪些地方有帮助?观察它们如何很好地回答具体问题,是否使用了优质的图像、表格或其他图形,以及页面是否易于浏览和导航。努力找出为什么这些页面被选为最有可能满足搜索者需求、提供帮助的页面。
与其纠结于关键词,不如努力改善真实的用户体验。如果你能让页面更具吸引力,更关注滚动深度、会话时长等指标,排名自然会提升。
最重要的是,要执着于“帮助性”。让第三方审视你的内容并分享其为何可能有帮助或没帮助,这本身会很有帮助。如果你感兴趣,我限时再次提供网站审核服务,做的就是这件事——审视你的页面,将其与谷歌系统所青睐的页面进行比较,然后给你提供大量改进思路。
我发现,即使我理解搜索引擎的构建初衷是持续学习并改进,以向搜索者展示他们可能觉得有帮助的页面,但我发现自己仍在与“为机器而非用户优化”的冲动作斗争。这真是个难以改掉的习惯!鉴于谷歌的深度学习系统正为一个目标不懈努力——预测哪些页面可能对搜索者有帮助——这也应该是我们的目标。正如谷歌关于“有帮助内容”的文档所建议的,人们通常认为有帮助的内容,是那些与搜索结果中的其他页面相比,具有原创性、富有洞察力并能提供实质价值的。