原文:https://moz.com/blog/vibe-coding-seo-tools-whiteboard-friday
大家好,我是Gus Pelogia,SEO产品经理,今天来和大家聊聊如何通过“沉浸式编程”打造你自己的SEO工具。
首先开门见山,我并不是要承诺你能打造出下一个革命性的AI SaaS产品并赚大钱。这其实是关于制作一些小工具,帮你节省日常时间,摆脱一堆枯燥的任务,从而加速工作流程。或许它能为你提供一个良好的初稿,供你自行审阅调整,最终变成属于你自己的东西。
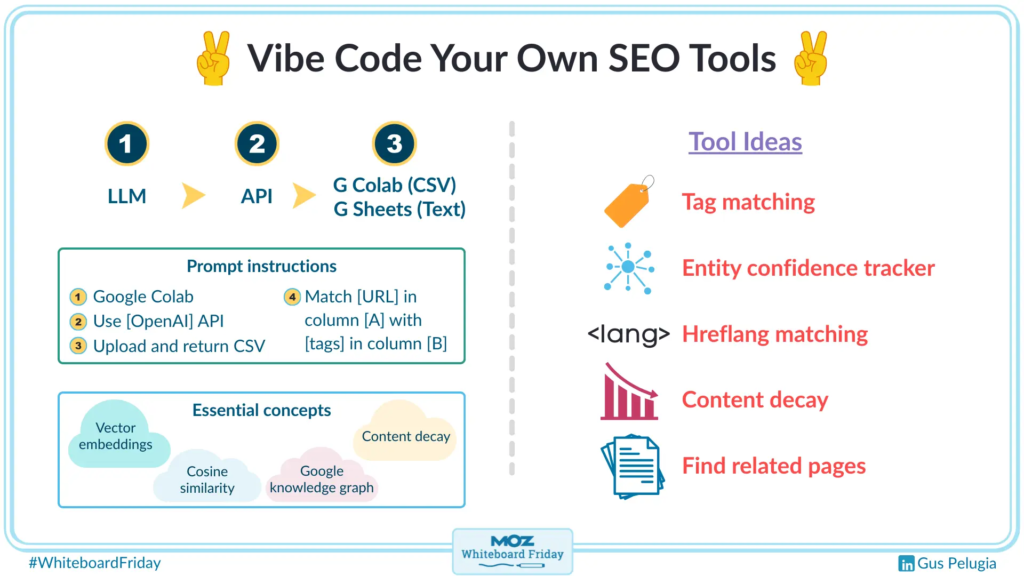
开始“沉浸式编程”需要什么
你需要三样东西来开启沉浸式编程,打造自己的工具。第一,你需要一个大语言模型。我从ChatGPT开始。你也可以试试其他的。
你可能需要一个API来连接你的大语言模型和代码运行环境。你的代码可以放在Google Colab上,这是一个在浏览器中运行的Python环境,无需安装任何东西。你基本上就是把代码从大语言模型复制粘贴过去,神奇的事情就会发生。或者,如果你想在更熟悉的环境中运行工具,也可以选择像Google Sheets这样的地方。两种方式都可以。
用来自Moz API的实时SEO数据,为你的洞察提供燃料
如何撰写你的提示词
现在,让我们简单了解一下这个过程。我不会给你读一整段提示词,这些可以放在随视频发布的博客文章里。但有几条规则你需要遵循。你可能会找到不同的方法,这是我的偏好,对我来说很有效,所以我很乐意分享。
我总是在提示词开头说明,我想要一个用于Google Colab或Google Sheets的代码,这样它就知道需要用什么语言和格式。它知道Google Colab上预装了哪些东西,所以你不用担心代码会出错或不如预期运行。
然后,你确保调用你需要的API。以我为例,我使用OpenAI的API。接着,确保你要求输出CSV格式。对我来说,我总是上传CSV文件,并且希望返回的也是包含我所要求代码输出的CSV文件。
最后,对你表格中的元素要非常直接和明确地说明。例如,A列是URL,B列是向量嵌入,C列是标签。无论是什么,都要确保声明每一列的内容,这样AI就能很容易地理解信息在哪里,以及应该放在哪里。
需要了解的核心概念
在这种情况下,有一些核心概念学习起来很重要,这些与我即将展示给你们的一些工具,以及我尝试和测试过的一些想法有关。你们完全可以自己去创造,这完全没问题。这正是本意所在。
但简单来说,向量嵌入本质上是将词语转化为数字,并为你的页面创建一个语料库。因此,页面上的所有词语在组合在一起时具有特定含义。嵌入将从你的页面中提取所有这些信息。然后是余弦相似度,它会查看页面A、页面B和页面C的语料库,或者甚至是不同列中的标签或任何其他信息,然后通过余弦相似度进行匹配,以说明A的信息与B的信息有多接近。
你可能也会尝试其他一些API。我用Google知识图谱API做过一些事情。这样你可以从谷歌获取一些信息,但你只需要知道你需要调用这个特定的API。所以,你可能需要知道API的名称之类的。你仍然需要获取自己的API密钥。有些是按使用付费的,比如OpenAI。有些可能有免费额度限制。如果你使用Gemini或Google知识图谱,至少在尝试一段时间内,你不会花任何钱。
提示词示例
我需要一个Google Colab代码,使用OpenAI来:
- 检查C列中现有的向量嵌入。
- 使用余弦相似度与每个地区(地区标识在A列)的两个建议进行匹配。
目标是找出每个地区的哪些页面彼此最相似,以便我们可以在这些页面之间添加hreflang标签。
我将上传一个包含这些列的CSV文件,并期望返回一个包含答案的CSV文件。
知识图谱
编写一个Google Apps脚本,调用Google知识图谱API,搜索特定查询(例如“泰勒·斯威夫特”),并打印@id、name、@type、description、url和resultScore字段。
如果查询未返回有效结果,请打印消息“查询不存在于知识图谱面板中”。
指导我如何将其添加到Google Sheets中,以每日触发更新。
使用来自Moz API的批量SEO数据和指标扩展你的研究
你可以通过沉浸式编程实现的工具创意
那么,让我们来看看沉浸式编程时你可以尝试的实际工具创意。
这些都是我亲自尝试和测试过的东西,我对结果感到满意。你总是可以做得更好,进行改进。但这确实能让你很好地体验到沉浸式编程可以做什么。这些东西我大概花了15分钟或半小时就做出来了。迈出第一步并发现“哦,这可行”是相当简单的。也许你想做些改进,然后完善代码和你的期望。
但我总是直接问ChatGPT。所以,如果某个页面的代码不工作,我会说:“我遇到了这个错误。你能帮我修复吗?”然后你会得到一段新代码,你再尝试新的,如此循环往复。
标签匹配
第一个是标签匹配。我想将某些行动号召与特定页面匹配起来。
我当时只是有大量的页面,不知从何入手。所以,我把标签上传到一列,把URL和向量嵌入上传到另外两列,然后让ChatGPT去匹配它们。嗯,我是把代码上传到Google Colab,通过向量嵌入和余弦相似度来实现的。
实体置信度追踪器
也许你想构建一个实体置信度追踪器。我们都知道如今谷歌是围绕实体运行的。谷歌有一个工具,你可以输入任何单词或短语,它会给出答案,告诉你谷歌是否将其理解为一个实体,以及对该实体的置信度有多强。
也许你想追踪你的品牌名称。或者以我为例,有段时间我痴迷于追踪自己的名字,检查我的知识面板是否存在,以及置信度是否在增加。于是我在Google Sheets上构建了一个东西,每天进行一次查询,并将置信度直接保存到我的Google Sheets中。
我只做了一次设置,它已经自动运行了一年。
Hreflang匹配
也许你不想手动进行hreflang匹配,或者至少不想从头开始。你也可以通过沉浸式编程构建一个工具,只需上传原始来源的向量嵌入,以及我想要匹配的页面的向量嵌入。
结果相当不错。就我而言,有很多不同语言的页面,它确实有效。它不局限于英语或同一种语言。它能给我一个很好的初稿。然后我可以去抽查,看看“这个页面和那个页面连接起来是否有意义?”这样你就能省去好几个步骤。
内容衰减追踪器
也许你想追踪内容衰减。
最近似乎每个人都在遭受流量下降的困扰。也许你想看看哪些页面随着时间的推移流失了更多流量。这样,你就不必一页一页地去查看,比如两年前有多少流量,现在有多少流量,你可以一次性批量处理,找出哪些页面表现更好,哪些表现更差,以及它们在一定时期内表现得更差或更好的程度。
这只是手动劳动,就像是处理数据。真正的工作,令人兴奋的部分,是你如何想办法让这些页面或内容重回正轨。
寻找相关页面
最后,也许你想寻找相关页面,这也是向量嵌入和余弦相似度的结合应用。
你可以上传你的页面列表和向量嵌入,它会找到很多匹配项。Moz博客上有一篇文章解释了如何做到这一点,我们也可以在帖子中提供链接。
这就是我们今天要分享的全部内容。我是Gus Pelogia,希望你也对沉浸式编程打造自己的SEO工具感到兴奋。
这将为你节省大量时间,无论是星期五还是一周中的任何一天,让你有更多时间去做真正重要的事情。谢谢。