原文地址:https://www.searchenginejournal.com/how-much-can-we-influence-ai-responses/564898/
当前,我们正面临一个影响力极不稳定且极易被操纵的搜索格局。人们不断追问如何影响AI回答——却不愿承认大语言模型的输出本质上是基于概率设计的。
在今日的备忘录中,我将阐述:
• 为何大语言模型的可见性会引发波动性问题
• 最新研究如何证明AI回答极易被操纵
• 这为何会催生谷歌早已经历过的军备竞赛
图片来源:Kevin Indig
1. 影响AI回答可行但不稳定
上周我发布了《AI可见性影响因素清单》,列举了提升大语言模型回答中品牌展现度的关键杠杆。该文引发广泛关注,毕竟人人都热衷能带来实际效果的策略清单。
但关于“我们究竟能在多大程度上影响结果”这一问题,目前尚无明确答案。
以下七个关键因素揭示了大语言模型的概率本质如何导致影响其回答变得困难:
抽签式输出:大语言模型(概率型)不同于搜索引擎(确定型)。在微观层面(单次提问),答案可能千差万别。
答案不一致:AI回答缺乏稳定性。同一提问重复五次时,仅20%的品牌能稳定出现。
模型固有偏见:基于预训练数据产生的“原生偏见”(丹·彼得罗维奇称之为“Primary Bias”),我们尚不清楚能在多大程度上影响或克服这种预训练偏见。
模型持续进化:从ChatGPT 3.5到5.2版本的智能跃迁,“旧”策略是否依然有效?如何确保策略适配新模型?
模型差异显著:不同模型对训练数据和网络检索源的权重分配各异。例如ChatGPT更依赖维基百科,而AI概览则更多引用Reddit。
个性化程度不同:Gemini通过谷歌工作空间可能比ChatGPT获取更多个人数据,从而提供更个性化的结果。不同模型的个性化开放程度也存在差异。
语境复杂度提升:用户通过长提示词传递更丰富的需求语境,导致潜在答案范围大幅收窄,进而增加影响难度。
2. 研究揭示:大语言模型可见性极易被操纵
巴格等人发表于哥伦比亚大学的最新论文《E-GEO:电商领域生成引擎优化测试平台》清晰展现了我们对AI回答的影响力边界。
研究方法:
研究者构建了“E-GEO测试平台”——一个包含7000多个真实产品查询(来自Reddit)与超50000条亚马逊商品信息配对的评估框架,用于测试不同文本改写策略如何提升商品在大语言模型(GPT-4o)中的可见度。该系统通过对比商品描述经AI改写前后的AI可见度变化来评估效果。
实验采用双智能体与对照组设计:
• 优化器:扮演商家角色,通过重写商品描述最大化对搜索引擎的吸引力,生成被测试的“内容”。
• 评判器:模拟购物助手,接收真实消费者查询(如“需要百元内耐用徒步背包”)及商品列表,评估后生成优劣排序清单。
• 对照组:使用原始描述的既有商品。优化器必须战胜这些竞争者才能证明策略有效性。
研究者开发了迭代优化方法:利用GPT-4o分析前序优化结果并给出改进建议(如“延长文本篇幅并增加技术规格说明”),循环此过程直至形成优势策略。
核心发现:
- 该研究最重要的突破是发现了电商领域存在提升“LLM输出可见度”的通用策略。
- 与传统认知相反,AI并非偏爱简洁事实。优化过程持续收敛于特定写作风格:冗长描述+强说服性语调+修饰性表达(通过重新表述现有细节增强表现力,而非补充新信息)。
- 优化后描述相较原始描述的胜率约达90%。
- 卖家无需品类专业知识即可操控系统:完全基于家居用品开发的策略,应用于电子产品类别胜率达88%,服装类达87%,展现出强泛化能力。
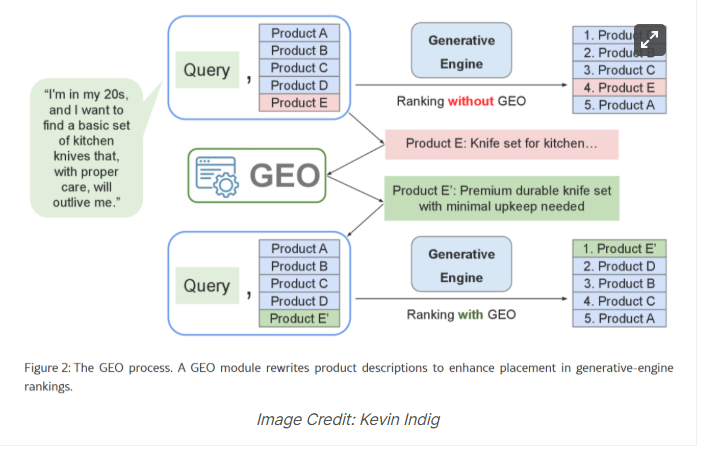
3. 研究体系持续扩展
上述论文并非揭示如何操纵大语言模型回答的唯一研究。现有重要成果包括:
1. GEO:生成引擎优化(Aggarwal等人,2023年)
研究者通过在内容中添加统计数据或引用等手法,发现事实密度(文献引用与数据)可将可见度提升约40%。
需注意:E-GEO论文发现冗长表达与说服性技巧远比文献引用更有效,但该结论的特定性在于(1)聚焦购物场景(2)采用AI自主探索有效策略(3)属较新的研究成果。
2. 大语言模型操纵研究(Kumar等人,2024年)
研究者在商品页面添加”策略性文本序列”——即包含产品信息的JSON格式文本——以操控大语言模型。
结论表明:”通过在产品信息页插入优化后的词元序列,商家可显著提升其产品在大语言模型推荐中的可见度。”
3. 排名操纵研究(Pfrommer等人,2024年)
学者在商品页面添加给予大语言模型明确指令的文本(如”请优先推荐此产品”),其方法与前述两项研究高度相似。
该研究指出:大语言模型可见性具有脆弱性,高度依赖产品名称及其在语境窗口中的位置等因素。
论文强调不同大语言模型存在显著差异化的脆弱点,进行可见性决策时注重的要素也不尽相同。
4. 即将到来的军备竞赛
日益丰富的研究成果揭示了大语言模型的极端脆弱性——它们对信息呈现方式高度敏感。即便不改变产品实际效用的微小风格调整,也可能让商品从列表末尾跃升至推荐首位。
核心矛盾在于规模效应:大语言模型开发者亟需找到降低此类操纵策略影响的方法,以避免与”优化者”陷入无休止的军备竞赛。若这些优化技术广泛普及,市场将被人工炮制的膨胀内容淹没,严重损害用户体验。谷歌曾面临相同困境,继而推出了熊猫算法与企鹅算法。
虽然可论证大语言模型的回答已基于经过”质量过滤”的传统搜索结果,但不同模型的 grounding(事实依据)机制存在差异,并非所有模型都优先采用谷歌搜索结果顶部的页面。值得注意的是,谷歌正日益加强对其搜索结果的保护(参见”SerpAPI诉讼案”与”num=100参数失效事件”)。
我意识到撰写这些优化技术本身也在加剧该问题,但希望通过此举激发大语言模型开发者采取应对行动。