原文地址:https://www.womenintechseo.com/knowledge/ai-search-optimisation-facts-vs-theories/
如今,领英上每天都能看到大量关于如何针对Google AI概览和ChatGPT等大语言模型进行优化的讨论,这类实践常被称为”生成引擎优化”或”AI优化”。
相关讨论常呈现两极分化:一方面,许多人持怀疑态度,指出许多大胆主张缺乏证据支持,市场上流传的多是未经检验的理论。这无可厚非。但另一方面,我个人认为分享假设与实验颇具价值——即便某些观点最终被证明有误,也能激发新思路,促使我们思考未曾触及的领域。这才是真正的价值所在。
本文旨在厘清已知事实与尚未验证的推测。我将重点分析四项证据充分、值得实施的策略,以及两项虽证据不足但易于测试的方案,并附上我收集的其他策略优先级矩阵。
术语说明:当前命名习惯尚未统一,有人用GEO,有人用AIO,也有人坚持沿用SEO。鉴于我与客户沟通时使用AIO这一术语,本文将沿用此简称。
为何AIO讨论热度攀升?
简言之:用户行为正在转变,数据为证。
Sparktoro与Datos(2024年)研究显示,超半数谷歌搜索以零点击告终,AI更加速了这一趋势。ChatGPT、Claude、Perplexity、必应Copilot及谷歌AI模式均在结果页直接呈现答案,意味着用户往往无需访问任何网站。
近期研究进一步印证:皮尤研究中心(2025年)报告显示,当出现AI摘要时,用户仅在8%的搜索中点击自然结果链接(无摘要时为15%)。据Semrush截至2025年3月数据,超13%的查询触发AI概览功能,月增幅达72%。
这一转变催生了SEO界所称的”大解耦”现象:内容可在AI摘要中获得海量曝光,却几乎无法带来流量。换言之,你的内容成为AI回答的原料,但你的网站可能从未被访问。这意味着传统SEO指标(点击、展现、排名)仅能反映半幅图景——用户从未抵达你的页面时,内容仍可能被查看、引用或标注。
作为SEO从业者,这或许是个略带风险的坦白:但作为用户,我确实更青睐直接给出食谱的AI概览,而非费力翻阅万字博客长文,只为寻找五天前在Instagram看到的”高蛋白三食材香蕉面包”的实际配方。
尽管如此,通过AI渠道抵达的流量往往更具价值。Seer Interactive(2025年)报告显示,某客户七个月内ChatGPT引流的转化率接近16%,而谷歌自然搜索仅为1.8%。这表明AI正在收窄流量入口的同时,大幅提升其精准度。
点击量减少但价值提升的矛盾现象,根源在于人们使用大语言模型的方式。RESONEO对87,725次ChatGPT对话的研究表明,多数查询聚焦事实与观点,而非产品本身。
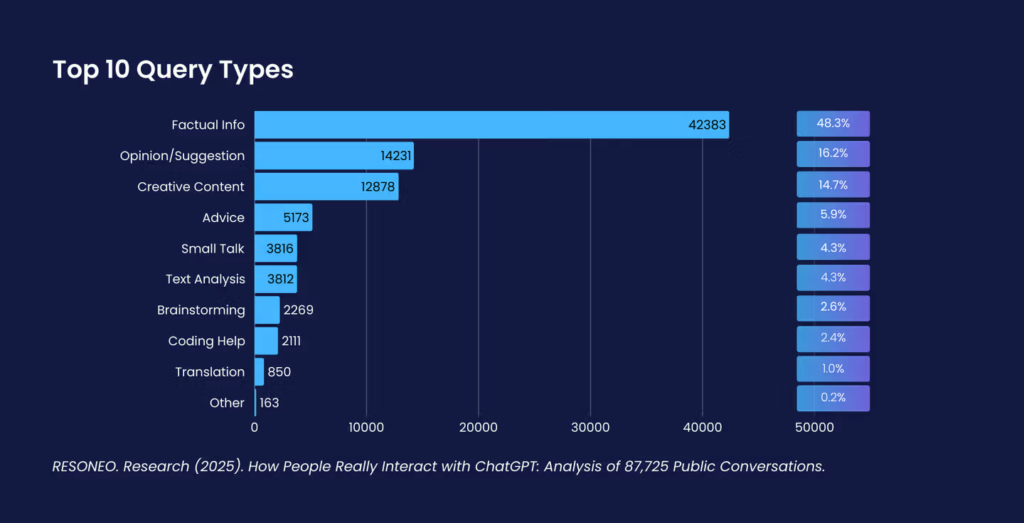
Semrush数据进一步佐证了这一观点:用户通常先通过ChatGPT进行探索和获取背景信息,但仍依赖谷歌进行验证、比较和行动导向的搜索。简而言之,大语言模型占据了用户旅程的前端,而谷歌在决策和转化阶段仍保持主导地位,如下图所示:
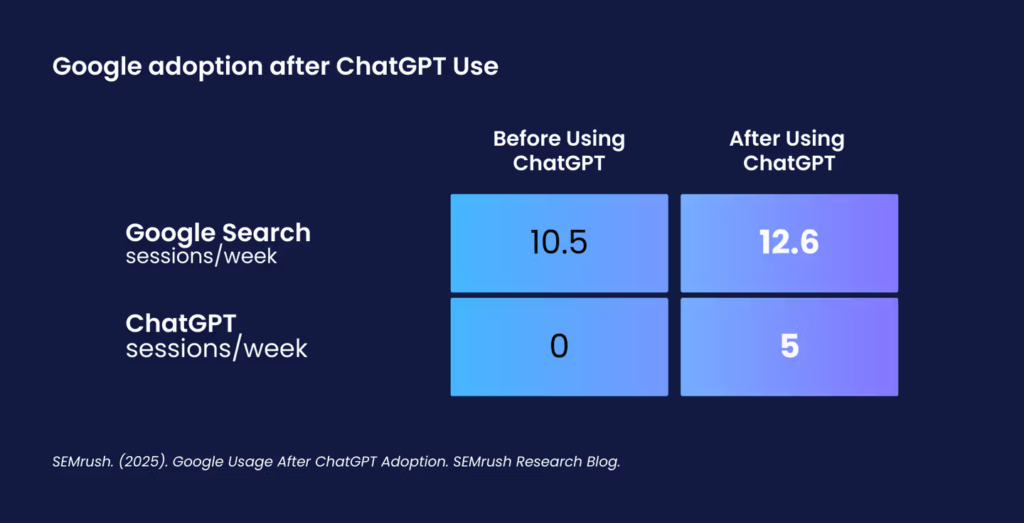
(图注:Semrush 2025年研究——用户采用ChatGPT后的谷歌使用行为)
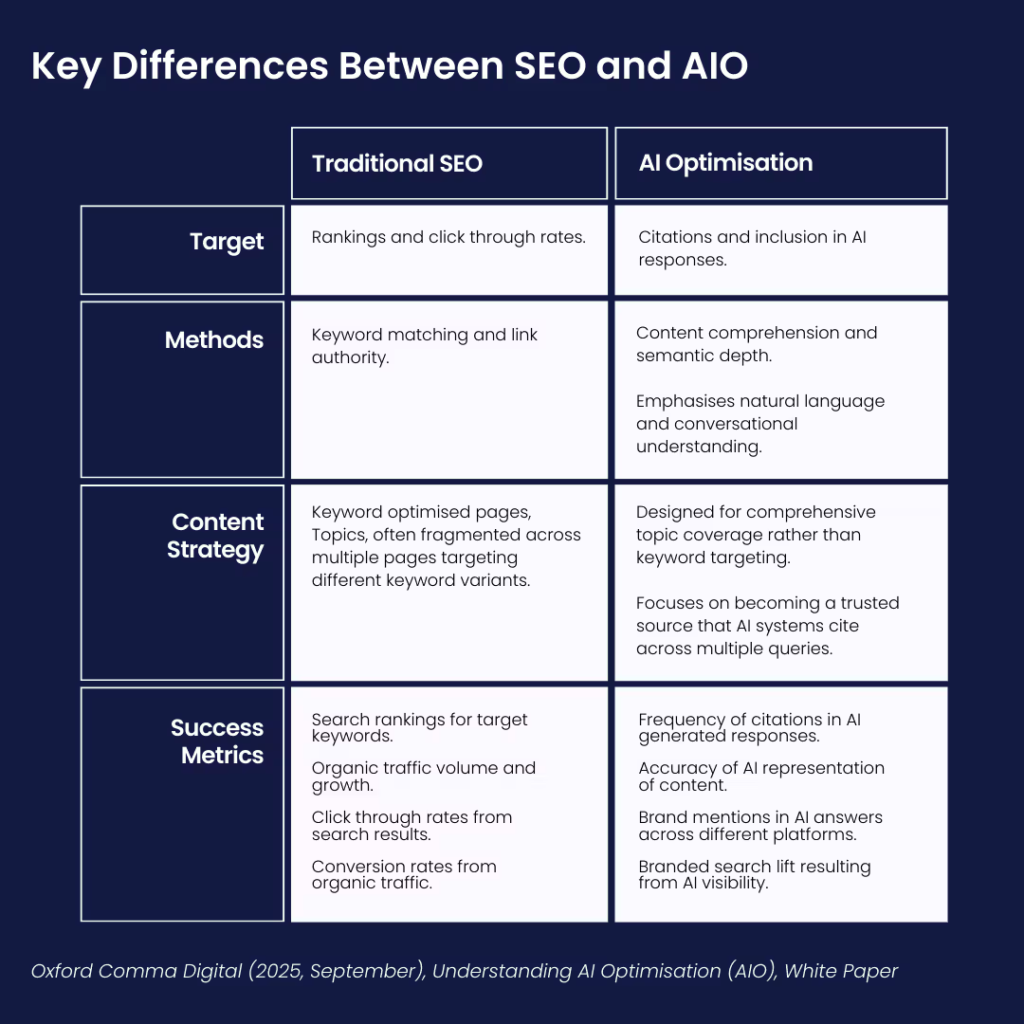
AIO与SEO有何区别?
搜索引擎优化(SEO)始终专注于提升在搜索引擎结果页中的可见性:旨在提高排名、增加点击和展现量。
而AI优化(AIO)则致力于让你的内容被ChatGPT、谷歌Gemini和Perplexity等AI系统理解、复用和引用。其目标不再是追求排名,而是成为这些AI系统在生成答案时能够放心引用的可靠信源。
好消息是:我们为SEO所做的多数工作仍然适用。核心原则——创作用户真正需要的内容、清晰组织内容结构、建立明确权威信号——依然至关重要。变化的是应用场景。
例如:
- 我们仍在为目标受众创作内容,但不再局限于单一关键词,而是力求全面覆盖话题,以便大语言模型更易解读
- 我们早已为SEO使用标题,如今这些标题同样帮助AI理解问题并构建回答框架
- 数字公关本是获取外链的关键,如今品牌提及本身也具有分量,其影响正从链接权重转向品牌资产
因此,不妨将AIO视为调整了焦距的SEO。具体策略往往相似,但驱动结果的底层逻辑已悄然不同。
以下是两者的对比示意图:
I优化核心策略:已验证的有效方法(证据充分,值得实施)
在AI优化/生成引擎优化领域,虽然存在大量杂音,但有几项策略已获足够证据支撑,可以确信值得关注并投入资源。这些并非理论推测,而是我们在平台文档、研究及实际应用中反复验证的模式。
以下是证据最确凿、建议优先投入的领域:
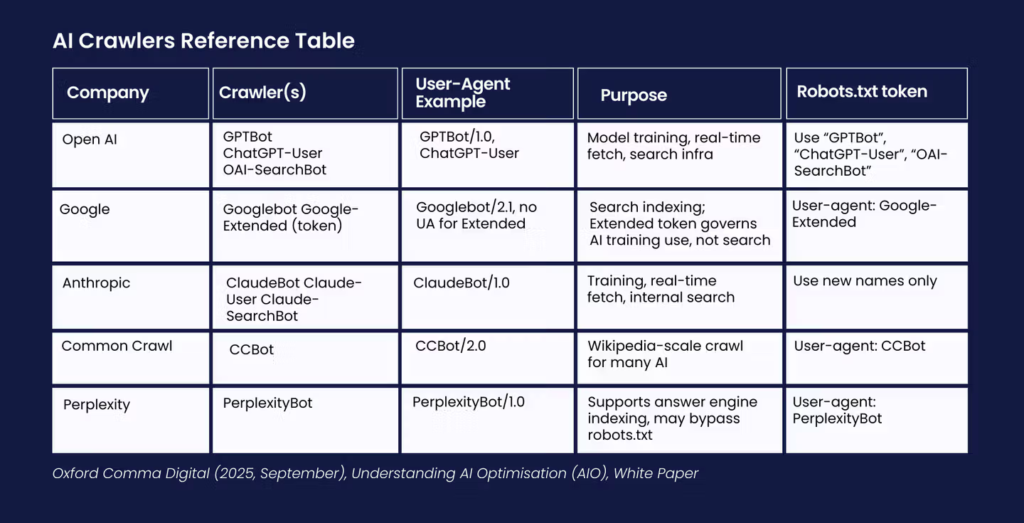
爬虫访问与权限管控
当前最明确的信号之一来自爬虫可访问性。
- OpenAI:通过GPTBot、ChatGPT-User和OAI-SearchBot进行网络抓取,分别用于模型训练、实时检索和基础设施优化。
- 谷歌:Googlebot持续为搜索建立索引,而Google-Extended则控制您的内容是否用于训练Gemini及其他模型。
- Anthropic (Claude):ClaudeBot与Claude-User专注于检索与索引构建。
- Perplexity:PerplexityBot为其答案引擎索引信息来源(有时可能忽略robots.txt协议)。
- Common Crawl (CCBot):为开源及商业AI模型提供基础数据。
您无需猜测这些爬虫是否访问过您的网站——直接查验服务器日志即可。虽然无法控制AI在获取内容后的具体使用方式,但通过robots.txt文件控制这些爬虫的访问权限(及访问范围)是完全可行的。这无疑是值得重点关注的调控杠杆。
(附:AI爬虫参照表)
结构化数据助力AI理解
谷歌与微软均已证实,结构化数据(如Schema标记)在传统SEO之外发挥着关键作用。它构成了大语言模型理解和复用内容的基础,因为这些模型依赖知识图谱和语义线索来解析信息。
效果差异可量化。Data.World的评估发现,当查询基于知识图谱而非原始SQL表时,大语言模型在企业问答任务上的准确率从16%跃升至54%。
那么哪些Schema类型最重要?
- 文章、人物、组织Schema:确立可信度与时效性。谷歌多年来一直推荐使用这些类型,虽然尚无官方确认它们能提升AI引用率,但有力证据表明它们能增强归属感和权威性。
- 产品、评论和评分Schema:共同构建清晰的产品视图:其特性、工作原理及客户评价。它们为AI系统提供明确的商业和质量信号。
- 常见问题解答(FAQ)Schema:自2023年谷歌缩减富媒体搜索结果中的FAQ展示后,其对SEO的效用降低,但对AIO仍具价值。其问答格式直接映射大语言模型生成答案的方式,使您的内容更易于被其理解和“锚定”。
话虽如此,Schema不应被视为一份待勾选的属性清单。它最好被理解为一个成熟度进阶之旅,对搜索和AI的影响逐层加深。
Schema App创始人Martha van Berkel的阐述非常精辟:
- 基础Schema:添加必要属性(如文章、产品、事件),使您的内容有资格显示为富媒体搜索结果。这是SEO的基本功,是起点。大多数人止步于此。
- 实体关联:在您自己的内容中定义并连接人物、产品、组织、地点等实体,并与可信外部来源(如Wikidata或谷歌知识图谱)建立关联。此步骤加强了AI系统对您内容的解读,有助于在非品牌查询中展现,并提升上下文“锚定”质量。
- 完整内容知识图谱:将您组织的内容构建为结构化的、可直接查询的图谱。它向生成式AI发送最丰富的信号,实现对您内容的更精准回答和更深层次推理。
我也推荐查阅Martha在Search Engine Journal上发表的文章;它们确实让我以全新视角看待Schema(而且,没错,甚至让我对实施它感到兴奋……这本身就说明问题)。
支持内容提取的内容架构
另一项已从“假设”范畴进入“已验证”范畴的策略是内容架构。
研究显示:
- 一项关于生成引擎优化的同行评审研究(Aggarwal等人,2024年)表明,列表和结构化格式能将引用召回率提升高达40%。
- Snowflake的RAG实验发现,当内容按自然段落划分(如标题和子章节)而非随机切块时,准确率提高了5-10个百分点。
- Han等人(2025年)发现,当要求大语言模型做出选择时,项目符号列表格式始终优于纯段落格式。
换言之,您的内容越清晰、结构越分明,AI系统就越容易提取并复用正确的部分。
实践中这意味着什么?
- 使用清晰的标题和副标题,使内容模块化。
- 尽可能以列表或表格呈现关键信息(就像我现在这样)。
- 善用直接映射大语言模型生成答案方式的问答格式。
需要注意的是,这并不改变您写作的主题(我们仍需创作人们搜索的内容),但确实改变了呈现方式。您不仅在为读者写作,也在为机器铺设路标。您让机器越容易追踪线索,它们就越有可能选取并复用您的内容。
权威信号与偏见影响入选
与传统SEO类似(谷歌奖励受信任的域名),生成式引擎也严重依赖它们已“信任”的品牌和来源。
证据表明:
- 提及比链接更重要:Ahrefs对75,000个品牌的分析发现,网络提及与AI能见度之间的相关性为0.664,而反向链接仅为0.218。链接并非无关紧要,但看起来大语言模型更关心一个品牌被谈论的频率,而非指向它的链接数量。
- E-E-A-T至关重要:谷歌和微软均已确认,文章、组织、人物和评论等结构化数据有助于大语言模型评估权威性。加上作者简介、资历和平台一致性,您能让AI更容易判断您的内容是否可信。
- 跨平台可信度:这不仅关乎您的网站。出现在播客、媒体报道、Reddit话题、Quora回答或Stack Overflow帖子中,都会成为机器可读的权威信号,因为大语言模型接受了这些来源的训练。
然而,AI并非对所有品牌一视同仁。研究表明,大语言模型严重倾向于已被广泛链接和引用的来源,这使得规模较小或较新的声音更难突破(Lichtenberg等人,2024年)。实验甚至发现,GPT-4和Llama-3始终将积极特质与Nike、Apple等全球品牌关联,同时低估本地竞争对手的价值。
如果这种趋势持续,AI搜索将不会“民主化”能见度;反而会放大已有优势参与者的领先地位。权威信号、持续提及和有意识的品牌建设不再是锦上添花。如果您希望在AI答案中出现,这些已变得至关重要。
尚属推测的领域(工作假设)
并非AIO中的所有策略都已被证实;有些(好吧,是大多数!)仍处于“可能有用,也可能是炒作”的范畴。这些值得关注,某些情况下也可以测试,但(目前)尚不能保证成功。我挑选了两个讨论最多的,但它们绝非唯一或最重要的。
llm.txt
可将其视为面向大语言模型的robots.txt。它不再告知搜索引擎爬虫可以或不可以做什么,而是为AI模型提供机器可读的指引。话虽如此,llm.txt仍处于实验阶段。截至2025年中,主流AI爬虫(OpenAI的GPTBot和ChatGPT-User、Anthropic的ClaudeBot、PerplexityBot以及Google-Extended)仍主要依赖robots.txt、结构化数据和Schema。
llm.txt未来可能带来回报吗?有可能。但就目前而言,我建议将其视为探索性策略,而非可靠的能见度提升工具。
个人认为,如果实施起来工作量不大(例如通过插件),不妨一试。它给您一个测试的机会,即使没有效果,也不会造成损害。
Markdown格式化
这个想法很有趣。没有大语言模型提供商确认将Markdown用作信号,但社区中有些人正在测试Markdown语法、标题(##)、加粗、代码块等是否能让内容获得优势。
这个想法之所以有吸引力,原因在于:大量开发者和技术内容(通常用Markdown编写)在AI答案中出现的比例异常之高。这可能是因为内容在被抓取、转换或存储到训练管道(如Common Crawl)中时,经常被扁平化为类似Markdown的形式。
因此,假设是:如果您的内容已经具备Markdown风格的标题、列表和表格,它可能在扁平化过程中保持更清晰的结构,从而更易于大语言模型提取和复用。
话虽如此,目前尚无确凿证据表明Markdown优于干净、语义化的HTML。最稳妥的做法仍然是确保您的HTML整洁且结构良好,以便在相同过程中同样能完好保留。
尽管如此……由于我最近一直在用AI构建一些应用和网站,我亲眼目睹了Markdown文件在保持上下文连贯性方面的实用性。这也是我真心好奇想将其作为AIO策略进行测试的原因。
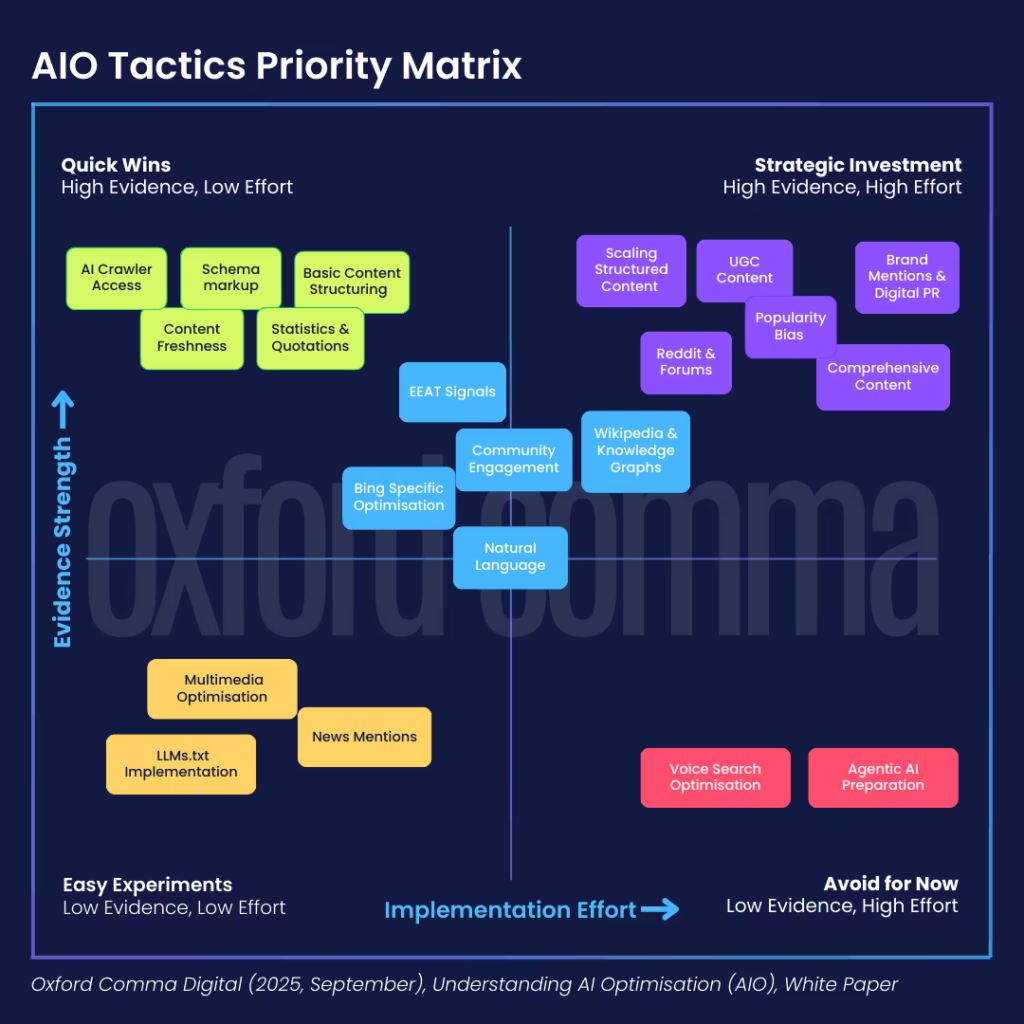
AIO优先级框架
您应如何确定AIO工作的优先级?我们牛津逗号公司内部目前正在使用“AIO策略优先级矩阵”。它提供方向性指导,而非固定配方,并将随着该领域的发展而演变。