原文地址:https://www.portent.com/blog/seo/pagination-tunnels-experiment-click-depth.htm
We’ve all seen pagination links — those little numbered links at the top and bottom of multi-pagecontent. They are used on blogs, e-commerce sites, webcomics, gallery pages, SERPs, and multi-page articles.
我们都看到过类似下图中的分页链接,在页首或页底出现的指向更多页面的链接,在各类型的网站上都能看到
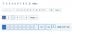
从用户角度来说,分页链接没啥可聊的。如果目前在浏览第一页,而你想要去到第二页的话,点击“2”(或者下一页),没什么问题。但是对于网络爬虫来说,会变得有点复杂。

上图是从爬虫视角访问某网站的效果图
爬虫基于已经爬取过的链接去寻找新页面,因此一个页面要被爬虫发现至少需要其中一个指向该页面的链接已被爬虫抓取过(也有例外,直接提交和xml地图就不需要指向链接)
对于树状结构的网站来说,很好理解。爬虫先访问首页,然后获取首页上的一级列表页链接,再获取一级列表页上的二级列表页链接,最后到详情页面。这样最多三个链接,爬虫就能访问网站上的任意一个页面。

但是如果是分页内容就会遇到问题
只有下一页链接
假设网站上有200个页面,我们把它们按顺序命名为1号到200号页面。
在第一种情况下,每个页面底部只有“下一页”的链接。如果你现在在第一页,点了下一页链接会转到第二页,继续点回到第三页。如果一直重复点,最终会来到第200页。
从爬虫角度来看,效果如下 上图中每个点代表一个页面,两点之间的链接标明上下游关系(大一点的是上游,小一点的是下游页面)。这张图主要说明的是第一种分页方式效率极低,原因如下:
上图中每个点代表一个页面,两点之间的链接标明上下游关系(大一点的是上游,小一点的是下游页面)。这张图主要说明的是第一种分页方式效率极低,原因如下:
1.当内容页埋藏极深的时候,也给了搜索引擎一个强烈的信号,就是你觉得这个页面不重要,因此搜索引擎的爬虫也不会频繁访问这个页面,可想而知排名自然也不好。
2.如果其中任一个页面出现问题(例如服务器故障),爬虫就无法访问出错页面下游的所有页面。
3. 无法并行抓取。也就是说,同一时间爬虫只能访问一个页面,不仅会降低爬虫抓取速度,也会影响爬虫的覆盖深度。
4.用户也许永远不会访问最深层页面。在这样的翻页结构下,即使用户想访问之前的页面,估计也会在无数次点击后放弃。
如何来改进呢?要不要试试
增加“末页”和“上一页”链接
我们来对分页做一些微小的调整:
 只需要101个链接就能触及到最深层的页面。现在爬虫有了两种抓取路径可选,一个是从第一页到第101页,另一个是从第200页到第102页,相比第一种分页方式,效率提高了一倍,不过还有改善空间。
只需要101个链接就能触及到最深层的页面。现在爬虫有了两种抓取路径可选,一个是从第一页到第101页,另一个是从第200页到第102页,相比第一种分页方式,效率提高了一倍,不过还有改善空间。
增加前后两页页码
这次我们不加“末页”链接了,但是加上当前页面的前后两页链接,第一页的翻页链接如下:
在第25页时翻页链接如下
这样从第一页开始,可以跳到第3页,再到第7页,依此类推。从爬虫视角,效果如下:
 有意思的是,这次的效果和上次差的不多。仍然是两条路径,还是需要100次访问才能触达最深层页面。
有意思的是,这次的效果和上次差的不多。仍然是两条路径,还是需要100次访问才能触达最深层页面。
同上一种分页方式的区别在于,路径分为奇数和偶数两种。现在又一个问题来了,这两种分页方式结合起来会产生什么样的效果呢?
增加“前后页”和“末页”链接
第一页的分页效果如下
第25页的分页效果如下
 只需要51次就可以遍历所有页面,效率继续大幅度提升,那抓取效率还有再提升的空间了吗?
只需要51次就可以遍历所有页面,效率继续大幅度提升,那抓取效率还有再提升的空间了吗?
增加前后18页页码
前面提到,加两个页码可提升一杯效率,要不索性干脆点,加上18个页码会怎么样呢?
第一页的翻页效果
第25页的翻页效果
 现在仅需7次就能抓完所有页面,可谓飞跃式的提升,不过这个分页样式的确有点丑,用户体验也不怎么好,我们只是作为实验来测试一下。
现在仅需7次就能抓完所有页面,可谓飞跃式的提升,不过这个分页样式的确有点丑,用户体验也不怎么好,我们只是作为实验来测试一下。
所以我们需要的是,同时提高抓取效率和用户体验的分页样式,例如:
增加中间点链接
第一页的分页样式:
第25页的分页样式
其实只是在前后两页页码的基础加了个中间页链接,但这一个链接就为爬虫创造了相当不错的入口。爬虫抓取效果如下:
 仍然是7次就能抓完,但是这个分页的样式可读性无疑更强了。
仍然是7次就能抓完,但是这个分页的样式可读性无疑更强了。
但如果页面数量级更大会怎样?
前面几个都是用200个页面做的演示,但是真实网站往往有数以千计的页面,那这个实验的结果还能重现吗?
这一回我们在20000个页面的基础做了测试
增加前后18页链接
 需要557次访问才能遍历所有页面,而200个页面的时候只需7词,差不多也是同比增长了将近100倍。因此页面数量和抓取深度大致呈线性比例。换句话说,页面翻倍,爬虫也需要翻倍的访问次数才能覆盖所有页面。
需要557次访问才能遍历所有页面,而200个页面的时候只需7词,差不多也是同比增长了将近100倍。因此页面数量和抓取深度大致呈线性比例。换句话说,页面翻倍,爬虫也需要翻倍的访问次数才能覆盖所有页面。
增加中间页链接
 神奇的是,只需要14次就能完成所有页面的访问。说明此方案的可扩展性非常好。页面数量和访问深度差不多呈对数关系,也就是说页面数量翻倍,抓取深度大概只增加了一层。
神奇的是,只需要14次就能完成所有页面的访问。说明此方案的可扩展性非常好。页面数量和访问深度差不多呈对数关系,也就是说页面数量翻倍,抓取深度大概只增加了一层。
现在问题又出现了 : 中间页分页方案值得推荐吗?
我们的答案是”视情况而定”
我们觉得用户体验的优先级是要高于搜索引擎收录的,因此尽快提供给用户优质相关的内容,无疑优先级更高。如果需要点很多次才能找到页面,那页码其实已经无关紧要了,重要的是缩减点击深度,降低用户浏览成本。
如果网站页面上了十万级,那中间页分页方案有助于爬虫更好的抓取页面,有助于深层页面获得更高的排名。
另外,中间页方案也会给普通用户造成一定困惑,对小型网站来说,“前后两页+末页”的方案或许是更好的选择。
最后,本次实验想提醒大家注意这一往往会被忽视的细节,而且说,分页的一点小改动会对爬虫效率和内容收录造成相当大的影响