原文链接:https://moz.com/blog/large-site-seo-basics-faceted-navigation
对于企业网站来说,尤其是电商网站或者分类网站,常会使用多维度导航的结构,这种结构能帮助用户更好地筛选出所需要的结果。然而对SEO来说,却是个噩梦,我之前服务过的客户,经常有由于多维导航而导致的数以百万计的筛选页面链接产生,而且还是可抓取可收录的,
之前有不少帖子深入研究过这个问题,这篇文章介绍了多维导航对SEO的具体影响(https://moz.com/blog/building-faceted-navigation-that-doesnt-suck),我也写过一篇文章http://www.86i87.com/2013/06/21/crawler-resource-distribution/
本文想解决的是把梳理这一类现象,并且给出对应的解决方案。我们面对的核心问题其实是:“有哪些方法可以影响Google对页面的抓取和收录,以及这些方法的优缺点是什么?”
简要回顾多维度导航
一句话概括,多维度导航是指网页上存在根据一系列属性(属性之间无明显相关性)筛选结果的导航形式。以下图为例,通过处理器类型、屏幕分辨率、外壳颜色等不同属性来挑选笔记本电脑,这样的展现方式就是多维度导航
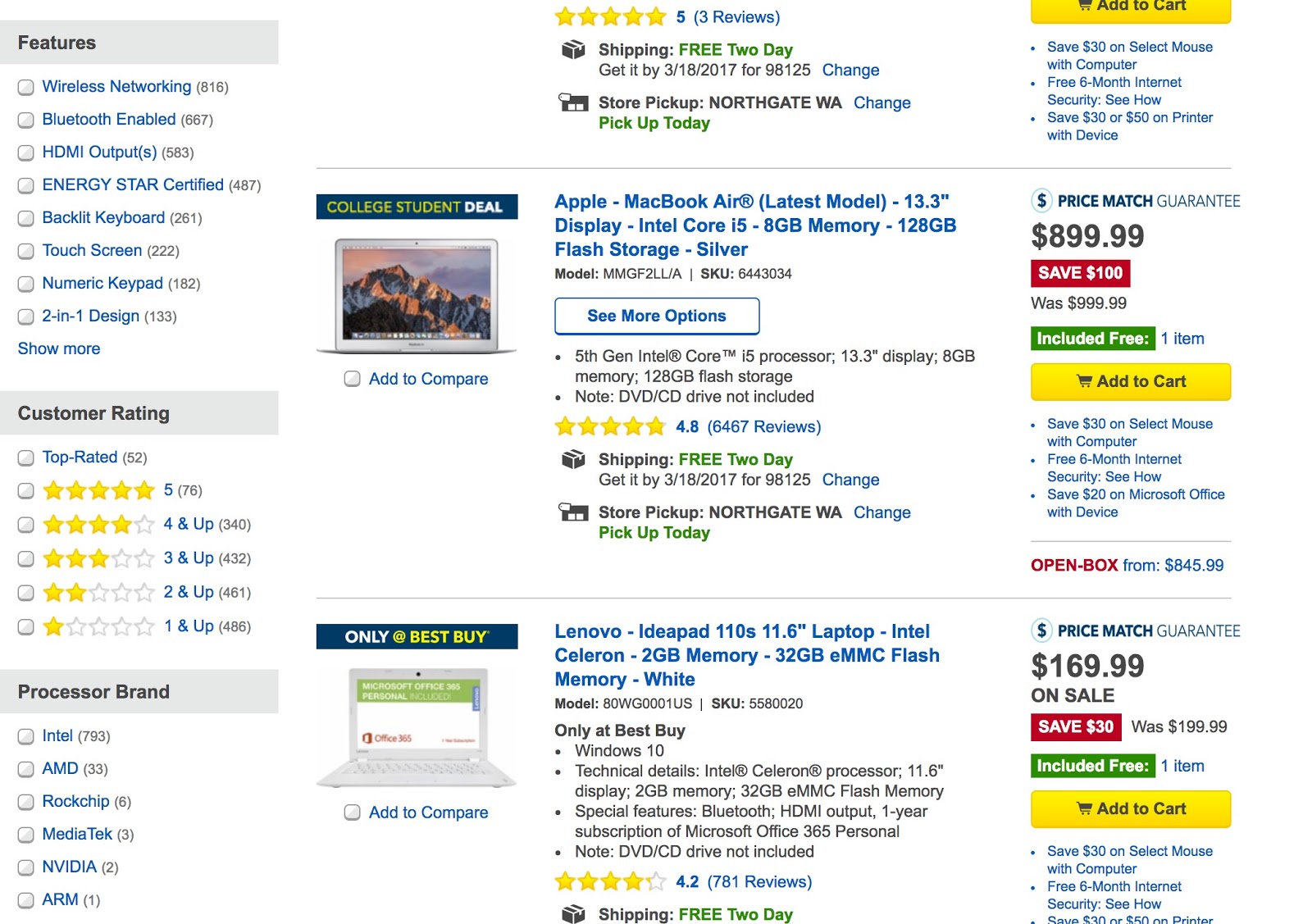
由于每种可能的排列组合属性的方式都会生成一种URL,多维度导航给SEO带来了几个问题
1.产生了大量的重复内容
2.消耗了有限的爬虫资源,而且返回给搜索引擎错误的信号
3.稀释了链接权重,同时链接权重传递给了本不该获得权重的页面。
来点具体的案例
看看一些多维度导航在网站上具体实施的例子以及对SEO的影响,你就知道为何要重视这个问题了。
Macy’s
在Google上搜索“site:https://www.macys.com/ black dresses”, Macys网站上符合这个条件的商品有1991个,然而Google却收录了12000多个页面。原因在于多维度导航设置的缺陷,可以从SEO的角度修复

Home Depot
再来看看Home Depot这个网站,搜索外开门会找到8930个页面,真的有必要让搜索引擎收录这么多相似产品的筛选页面吗?其实未必,当然也可以通过下面介绍的方法修复这个问题。

对于大型电商网站来说,这样的情况还真不少,我想说的是,其实这些网站在多维度导航这件事上还可以做得更阿基SEO友好一点。
多维度导航SEO解决方案
解决这个问题,首先要明确哪些内容需要被收录,哪些则是要避免收录的,以及如何达成这两个目的、我们来看看咱们手头都有哪些武器?
“Noindex, follow”
Noindex标签是大多数人首先想到的方案,该标签唯一的作用就是告诉爬虫别收录这个页面,因此对避免收录这个目的来说相当有用。
不过,虽然使用Noindex标签可以有效减少重复页面收录,但仍然会消耗爬虫资源,以及这些重复页面会接受链接权重,因此有效页面能获得的权重就会减少。
操作实例: 以上文提到的Macys网站为例,如果想收录“black dresses”页面,但是不想收录“100元以内的black dress”页面,在后面的筛选页面里面添加noindex标签就可以了。不过爬虫资源和链接资源的消耗是无法规避的。
Canonicalization
使用Canonical标签也是常见的应对方法。Canonical标签的意义在于告诉Google爬虫这一类页面相似度很高,只需要抓取网站返回给你的标准版页面就可以啦。Canonical标签的设计初衷就是为了解决重复内容的问题,而且链接权重也会被集中到标准版页面,看起来是个不错的方案。
可惜的是,Google爬虫的爬行资源还是会被消耗。
操作实例: /black-dresses?under-100/ 可以设置canoncial的URL指向 /black-dresses/.既解决了重复问题,又解决了链接权重分散的问题。
Robots.txt屏蔽
禁止爬虫抓取这部分筛选页面当然也很有效。好处是:速度快,操作方便,并可以自定义拼比页面。不过还是会有不好的影响:首先屏蔽之后,链接权重就好像被黑洞吸进去一样,彻底没有了;另外,有的时候Google也不会遵守Robots协议。比如下图,就是被Robots屏蔽的页面依然会展现在搜索结果里。

操作实例: 在Robots.txt中disallow *?under-100* .可以杜绝Google访问任何包含under-100参数的页面,然而如果有其他链接指向这类URL,Google仍然会收录。
“Nofollow” 不想收录的链接
可以通过Nofollow多维度导航链接来解决抓取资源消耗的问题,可惜的是,nofollow标签也无法彻底解决问题,这些重复页面依然会被收录,同时链接权重也依然会丢失。
操作实例: 给指向不想被收录的页面的内部链接都加上nofollow标签,意思就是告诉Google别去抓这些页面啦,抓点别的内容更好。
一起解决以上所有问题
首先,如果导航结构还没上线的话,我强烈建议通过不改变URL的方式实现多维度导航(多数通过js脚本实现),这样既不妨碍用户体验,又不会生成多个URL。可惜也有问题:有一些核心导航也能有被收录的价值,还是得给这类页面做入口。
下面这张表格也许能看得更清楚一些:
| 解决方案 | 是否解决重复内容问题? | 是否解决爬虫资源问题? | 是否解决链接权重传递问题? | 是否允许外部链接传递权重? | 是否允许内部链接权重转移? | 备注 |
| “Noindex, follow” | Yes | No | No | Yes | Yes | |
| Canonicalization | Yes | No | Yes | Yes | Yes | 只能用于相似页面 |
| Robots.txt | Yes | Yes | No | No | No | Robots屏蔽的页面仍然有可能被收录 |
| Nofollow | No | Yes | No | Yes | No | |
| JavaScript | Yes | Yes | Yes | Yes | Yes | 投入更多技术资源 |
所以有完美的解决方案吗?
首先,并没有一劳永逸的方案,完美的做法应该是以上方案的有机结合。下面这个例子也许适用于大多数网站,但是更重要的是了解自己网站的结构和问题所在,再给出针对性的方案。
制定方案之前先问自己一个问题,对你的网站来说,爬虫的抓取资源和链接权重哪个更加重要?不同答案意味着不同的做法。
例如:不在乎链接权重的损失,只想更好地分配爬虫的抓取资源,我会建议这样做:
1.目录页、子目录可以保留目前的可抓取状态( /clothing/, /clothing/womens/, /clothing/womens/dresses/类似这样的地址)
2.对单个目录页而言,只允许带一个筛选条件的URL被访问
a. 对包含一个及以上筛选条件的页面,该页面上的筛选链接都加上nofollow属性(比如/clothing/womens/dresses?color=black/)
b.对包含两个及以上筛选条件的页面,同时添加Noindex标签(比如/clothing/womens/dresses?color=black?brand=express?/)
3.评估一下那些筛选条件对SEO有利(例如颜色和品牌名),把这些筛选条件加入白名单,做到可被搜索引擎抓取和收录
4.正确设置canonical 和 rel=prev/next 标签(可参考这篇文章http://www.gsqi.com/marketing-blog/how-to-set-up-pagination-rel-next-prev/)
上述做法可以逐渐缓解多维度导航给网站带来的问题,另外这个方案结合了集中不同的处理方法,包含了nofollow,noindex,canonical标签的组合使用,以获得更好的效果。
其他注意事项
有两点需要单独拎出来说一下
面包屑很有用
如果在目录页/子目录页没有面包屑导航, 就是给自己挖了个深坑。因为对于结构复杂的网站来说,面包屑是帮助爬虫理清网站结构最好的工具。
固定好URL中的筛选参数
某些情况下,有的网站筛选条件选择的顺序不一样,也会产生不同的URL,这样会让重复页面成倍增长,所以请务必写死筛选条件的排序。
总结
希望这篇文章能给你更多改善多维度导航,提升搜索表现的想法,其实主要就下面几点:
1.多维度导航用户体验很好,但是往往不利于SEO
2.多维度导航对SEO影响最大的点在于:重复内容、抓取资源浪费、链接权重不能有效传递
3.最核心的问题是:如何控制Google的爬行和收录?
4.没有万能的解决方案,好的做法是组合以下工具:noindex,follow;canonical;robots文件;nofollow;ajax/js.
5.设计解决方案的前提是对链接权重和爬虫资源有个优先级的判断。
【翻译小结】其实这篇文章针对的是google,那百度又是什么情况呢,因为根据经验,canonical标签对百度用处不大,有什么替代工具呢?百度是不是也存在爬虫资源的分配和链接权重传递的问题呢?老实说,只有亲自测试过才知的,我其实也好久没有做过类似改动,因此也挺想看到类似的分享。