
简介
这是有关大型电子商务网站(如Skroutz.gr)上SEO的技术方面的故事,咱们家网站每天有近一百万次访问,今天我们来看看如何一年半前发现的一些重大技术问题的处理案例。
让我们来窥探我们努力的里程碑,本案例研究涵盖了这些里程碑。 在过去的1.5年中,我们做了这些事
1.将索引大小减少1800万个URL,同时提升了展示次数,点击次数和平均排名。
2.创建了一个可以处理数百万个URL的实时爬虫分析工具。
3.为重要的SEO索引和爬虫问题定制了自定义警报机制。
4.自动化了合并或拆分电商页面的SEO技术流程。
如果您有兴趣了解我们为什么以及如何完成上述所有工作,请往下看!
第1部分:SEO分析(2018年2月)
›哪些问题启动了我们的分析
›我们如何进行分析
第2部分:行动计划和执行(2018年2月-2019年6月)
行动计划
执行
第3部分:结果
我们学到了什么
But before we take off, let us introduce ourselves.
但是在我们开始之前,先做个自我介绍
Skroutz.gr是希腊领先的价格比较搜索引擎和电商网站,也是Similar web全球排名前1000的网站。 Skroutz.gr帮助商家在2018年产生了5.35亿欧元的商品总销售额(GMV)(约占希腊零售电子商务GMV总额的20%)。
除了主要的B2C价格比较服务外,Skroutz.gr还为希腊市场提供了B2B价格比较服务和新的食品在线订购服务,即SkroutzFood。 最后,Skroutz.gr拥有自己的500多个商人的市场。
大型网站中的SEO挑战:Skroutz.gr的 案例
那么,拥有数百万个页面的网站会遇到哪些挑战?
首先,想象一下当您为一个中等规模的网站优化排名时遇到的困难,例如关键字研究和监控,站内SEO等。现在,考虑一下百万页大小的网站上的相同问题; 您必须处理大量数据并以不影响质量的方式来使事情自动化。
除此之外,SEO不仅仅是排名…
事实上,大型网站SEO还有另一个大麻烦:爬网和索引编制。 这些重要步骤甚至在Google对您的内容进行排名之前就已经发生,并且在大型网站上可能会变得极其复杂。
注释:在本案例研究中,我们重点研究了Google搜索引擎和GoogleBot。 但是,所有搜索引擎的运行方式都相似。
发生的大多数问题主要与抓取预算和重复内容有关。 进一步来说:
抓取预算:Google对每个网站都有抓取率的限制。 如果该网站的网址少于数千个,则通常可以对其进行全部爬墙。 但是,如果您的网站上有一百万或更多的页面,则需要改进完整结构,以便爬虫可以更轻松地访问和抓取最重要的页面
重复的内容:如果相同的内容出现在多个网址上,则说明您有重复的内容。 虽然重复内部不会遭受搜索引擎的惩罚,但是有时会导致重复的内容排名和流量下降。 正如Moz所说,发生这种情况是因为GoogleBot *不知道是将链接指标(信任度,权重,锚文本,链接资产等)定向到一个页面,还是将其分隔在多个版本之间,其次,它不知道要为查询结果给到哪个页面作为排名。

例如,Skroutz.gr在3,000个类别中拥有3,000,000多种产品。 它还使用多维度导航,该导航具有13,000多个过滤器(可以组合-最多3个过滤器),三个排序选项和一个内部搜索功能。 这些选项大多数都会产生一个唯一的页面(URL)。
因此,大型网站的管理员必须:
1.自动化监视站点的SEO性能
2.提防低质页面或重复的页面,以免干扰Google对核心页面的收录和排名
3.控制哪些页面想要给到搜索引擎进行抓取和建立索引
第1部分:SEO分析(2018年2月)
哪些问题引发了我们的分析
如果一切顺利,您的大多数排名都位于前3位,并且自然流量的增长是稳定的,那么很难怀疑SEO方面出现了什么问题。 早在2018年,Skroutz.gr就属于这种情况。
如果您在下面的过去五年中查看Google Analytics(分析)会话图表,很明显,我们的流量每年都在以自然增长15-20%的速度增长,甚至超过了每月3000万次会话(其中80%是自然流量)。
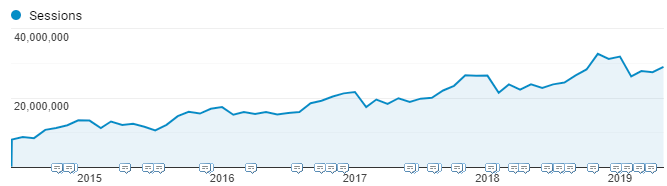
那么,SEO没有按预期进行的第一个信号是什么? 三个问题引起了人们的注意,特别是当我们意识到它们之间的相关性时。
1. 收录数量
第一个是我们在Search Console上看到的索引大小(近2500万个URL),与我们认为拥有的“真实”页面数相比。
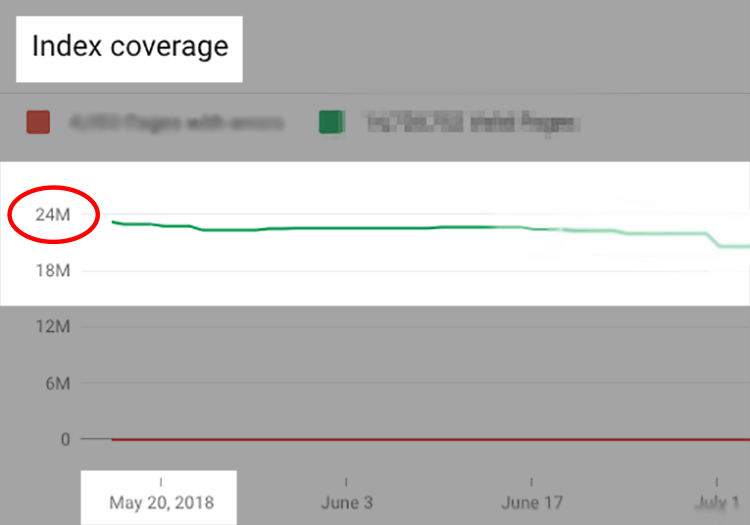
2. 新页面被收录和获得排名的时间变长了
如果我们不得不将一个宽泛的目录分为2-3个子目录,则排名恢复的延时情况更加明显。 这种拆分会产生许多新的URL,以及许多301从旧URL重定向到新URL(例如,旧的带筛选条件的URL)。
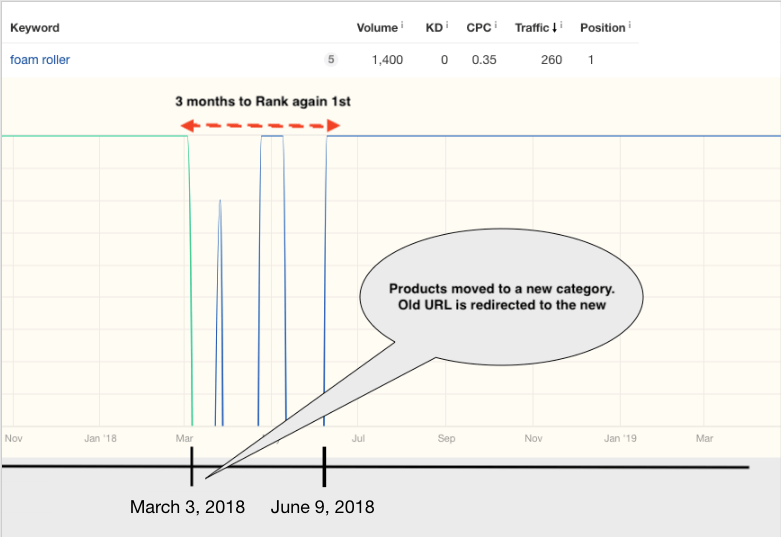
例如,查看 Ahrefs提供的历史数据,找到关键词“泡沫轴”。 泡沫滚筒产品以前被归在运动平衡设备(表中的绿线)内容。 2018年3月3日,内容团队决定创建一个名为Foam Rollers(表中的蓝线)的新类别,并将相关产品移至该目录内。
如图所示,18年初,我们的内部搜索页面skroutz.gr/c/1338/balance_gym.html?keyphrase=foam+roller的“泡沫轴”上排名第一。 在2018年3月3日,我们创建了skroutz.gr/c/2900/foam-rollers.html类别,并重定向了第一个URL以及数百个相关URL(例如skroutz.gr/c/1338/balance_gym.html ?keyphrase = foam + rollers)。
根据前几年的统计数据,在合并页面后,新的网址只需几天到几周即可恢复排名。 然而,在这种情况下,花了将近三个月才排名第一。 除此之外,旧的重定向URL仍会保留数月的索引,而不是几天后被删除。 这表明随着时间推移,我们的抓取效率有所下降。
3. Google索引里更新标题描述的时间越来越长
标题和元描述在Google索引中的更新速度不如前几年,尤其是对于访问量较低的网页而言。
As a result, fresh content and schema markups (availability, reviews, and others) weren’t reflected in Google SERPs within a reasonable time.
结果,在合理的时间内Google SERP中没有体现最新的内容和新的结构化数据(商品是否有库存,商品评论及其他信息)
我们是怎样分析问题的?
第一步 – 问题概览
首先,我们想验证我们对2500万页索引量的担忧。 因此,我们想找出2500万个页面中实际上应该包含在SERP中的页面
我们深入研究了不同类型的目标网页,并计算出以下估算值:
1.使用Google搜索命令,每种类型当前被索引的页面数
2.使用内部分析工具分析不同类型页面在总流量中所占的份额
3.根据当前或潜在访问量等数据,我们应拥有的索引页数
| 页面类型 | 目前收录页面 | SEO流量占比 | 应该被收录的页面 |
|---|---|---|---|
| 首页 | 1 | 24% | 1 |
| 产品页[like Apple iPhone XR (64GB)] | 4.5M | 20% | 3M |
| 无筛选目录页 [like Sneakers] | 2500 | 25% | 2450 |
| 带筛选条件目录页 [like Stan Smith Sneakers or Nike Sneakers] | 2.5M | 10% | 1.5M |
| 内部搜索结果页 [like ps4] | 14M | 20% | 1M |
| 其他页面 (Blog, Guides, Compare Lists, Pagination, Parameters) | 4M | 1% | 1M |
| 合计 | 25M | 100% | 6.5M |
结果是令人震惊的
- Actually indexed pages versus our estimated pages differed by a count of nearly 19 million URLs
- The Internal Search pages index bloat seemed the most crucial issue. Probably we had tons of meaningless, regarding traffic, indexed pages
- Product and Filter Pages had a reasonable amount of low-quality pages
- Pagination Pages were the top suspect of the 4M pages of “Other Pages” type. This announcement might explain why 🙂
1.实际被编入索引的页面与我们估计的页面之间的差异约为1900万条
2.内部搜索页面索引膨胀似乎是最关键的问题。 就访问量而言,这些被索引的页面对我们来说毫无意义
3. 产品和带筛选条件的目录页面上有相当数量的低质量页面
4.分页页面是“其他页面”类型的4M页面的最大可疑因素。
为了解决这些问题,大家一致决定,我们应该先快速行动起来,然后在实践中提出更详细的解决方案。
第二步 -组建团队,研发工具
经过以上分析,我们组成了SEO虚拟团队,其中包括SEO分析师,开发人员和系统工程师。 该团队将更深入地分析问题,制定行动计划并实施建议。
在我们的第一次会议上,我们决定需要进行更精细化的爬虫分析才能完全了解问题的严重性。 我们选择设置内部实时抓取监视工具,而不是采用付费解决方案,原因在于:
可扩展性:分析超过2500万页面,并在每次需要时查看爬虫的行为变化。
实时数据:在进行重大更改后可以立即查看对爬虫行为的影响
定制:定制工具并添加针对每种情况的所需功能
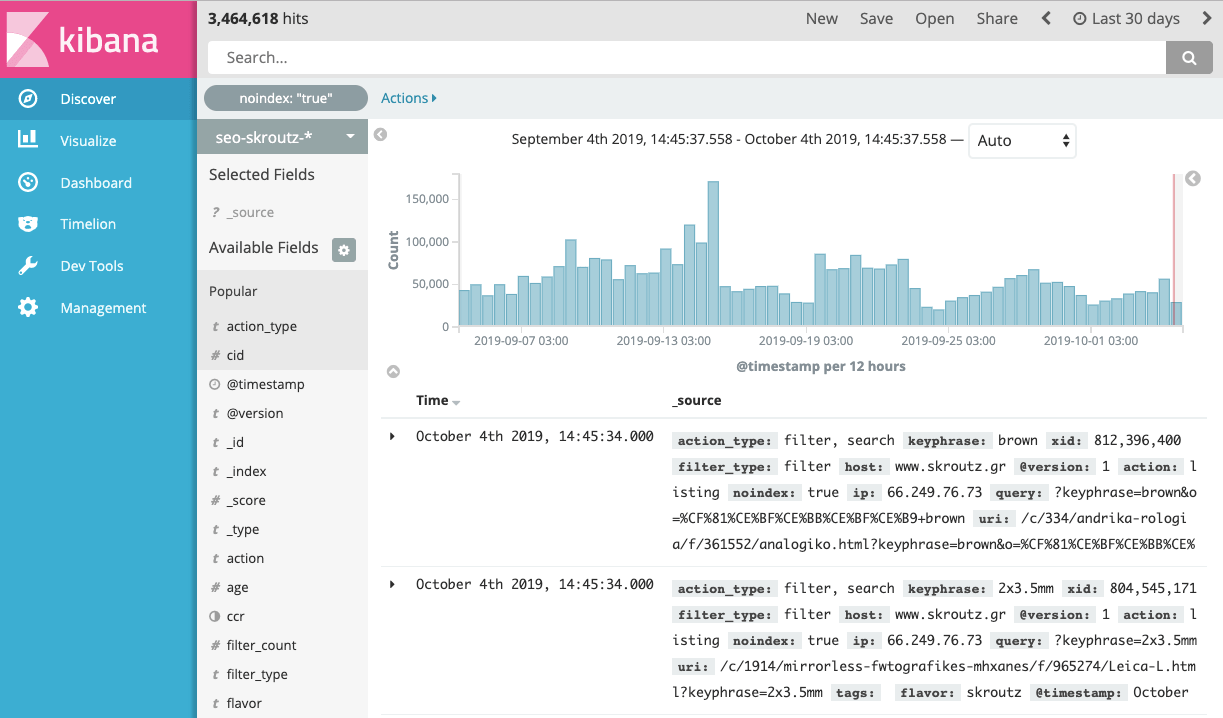
.由于我们已经对ELK Stack(这是我们的主要分析工具之一)有一定的经验,因此我们决定使用Kibana设置内部爬虫监控工具。
Kibana是一个功能强大的工具,它帮助我们发现了许多重要的爬虫问题。 如果我们只需要选择一件事来扩展我们在爬虫监视中的功能,那将是带有丰富元标记的网页浏览注释。 通过使用丰富的元标记,URL会携带其他结构化信息,从而提供了查询特定子集的方式。
例如,假设我们有这样一个网址:skroutz.gr/c/3363/sneakers/m/1464/Nike/f/935450_935460/Flats-43.html?order_by=popularity
我们在该URL上注入的一些信息如下:
页面类型:筛选页面(其他选项可以是内部搜索页面)
类别ID:3363
应用的筛选条件数量:3
筛选类型:普通条件(平底),品牌(耐克),尺寸(43)
HTTP状态:200
URL参数:?order_by = popularity
有了这类信息,我们就能回答以下问题:
GoogleBot是否对启用了两个以上筛选项的网页进行爬网?
Googlebot抓取一个特定的热门目录页的数量?
GoogleBot抓取的最多的URL参数是哪些?
GoogleBot是否会抓取带有默认为nofollow的筛选项(如“大小”)的页面?
提示:您不仅可以将这些信息用于SEO,还可以将其用于调试。
例如,我们使用页面加载速度信息来监视每种页面类型(产品页面,类别页面等)的页面速度,而不是仅监视平均站点速度。
想想看,可以通过简单的Kibana查询来深入查找Googlebot的抓取模式。
我们如何注入URL信息
我们使用自定义HTTP头。 这些header信息流经我们的应用程序堆栈,并且任何组件(例如我们的实时SEO分析器)都可以提取和处理所需的信息。 最后,在将响应返回给客户端之前,我们将元标头从请求中删除。:
综上所述,Kibana使我们能够执行三项关键任务:
1.实时查看每一个Google Bot的爬行数据
2.使用产品类别,URL类型(产品,内部搜索等)等过滤器可以缩小结果范围
3.创建可视化或表格来深度监视爬虫行为,折线图显示类别筛选条件,内部搜索和产品页面的月度数据。
第三步 – 爬虫数据的分析结论
在对抓取报告,流量统计信息以及至少一个月的实时数据和前几个月的日志数据(至少十个月)进行连续监视之后,我们进行了很多深入研究,终于有了我们的第一个发现。 最重要的内容如下:
好的地方
GoogleBot几乎每天都抓取我们最受欢迎的产品页面(450万个页面中有20万个)。 这些页面具有较高的权重和许多反向链接,所以这是预料之中的
不好的地方
1.谷歌每天的平均抓取预算为100万,我们的索引为2500万,因此Googlebot每天只能抓取我们总页面的4%
2. 我们每日抓取预算的50%以上是内部搜索页面。 但是大多数内部搜索页面根本没有流量
3.除了上述内容之外,我们还看到了一个奇怪的模式,大量被抓取的内部搜索页面URL都包含相同的通用关键字。 例如,成千上万的URL上存在“ v2”关键字。 例子:
skroutz.gr/c/3363/sneakers.html?keyphrase=v2
skroutz.gr/c/663/Gamepads.html?keyphrase=v2
skroutz.gr/c/1850/Gaming_Headsets.html?keyphrase=v2
我们从未想到过内部搜索与目录页面的组合会以如此高的速度被爬取和索引。
第二部分:执行计划 2018.2 – 2019.6)
行动计划
经过分析,我们的团队决定了下一步行动计划。 根据分析结果,最关键的问题是带有内部搜索查询的URL的抓取量和索引量异常。 我们怀疑索引量的异常增长是第1部分中提到的问题的主要原因。
我们制定了后续几个月的行动计划,内容包括
A. 爬虫抓取资源优化项目(第一优先级)
1查找并修复爬虫漏洞,这些漏洞会带来越来越多的可索引内部搜索页面
2.通过相应地删除或合并内部搜索页面的来减小其收录数量
B. 爬虫抓取资源优化项目(第二优先级)
1.当我们创建新类别或将两个或多个类别合并为一个类别时,提升新URL被抓取和被收录的速度。
2.创建重要爬虫抓取问题的警报机制
执行回溯
A. 爬虫抓取资源优化项目(第一优先级)
1. 寻找爬虫陷阱
首先,我们想看看我们的链接结构中是否存在任何漏洞,从而使Googlebot可以找到大量异常的内部搜索页面。
在开始执行之前,全面了解搜索引擎的工作方式以及内部搜索页面的创建方式将很有帮助。
Skroutz.gr的搜索功能简介
正如我们之前所说,Skroutz.gr始终将搜索体验放在首位,这意味着我们绝大多数用户都是在搜索产品,而不仅仅是浏览产品。 实际上,我们每天有超过60万次搜索!
因此,我们有一个由5名工程师组成的专门搜索小组,他们在用户在搜索框中键入查询后会努力提高用户的体验。 搜索团队创建了数十种机制,可以使我们的搜索引擎在大多数情况下向用户返回高质量和相关的结果。 因此,我们在这些页面上的跳出率非常低(低于30%),接近网站的平均水平。
内部搜索页面是如何被创建的?
首先,我们要明确,Skroutz.gr的所有内部搜索页面在URL上都包含参数“?keyphrase =”
内部搜索页面有2种类型;
用户在搜索框中输入查询后,我们的搜索引擎将尝试从所有类别中找到最相关的结果并返回
- 无目录的搜索结果: skroutz.gr/search?keyphrase=shoes
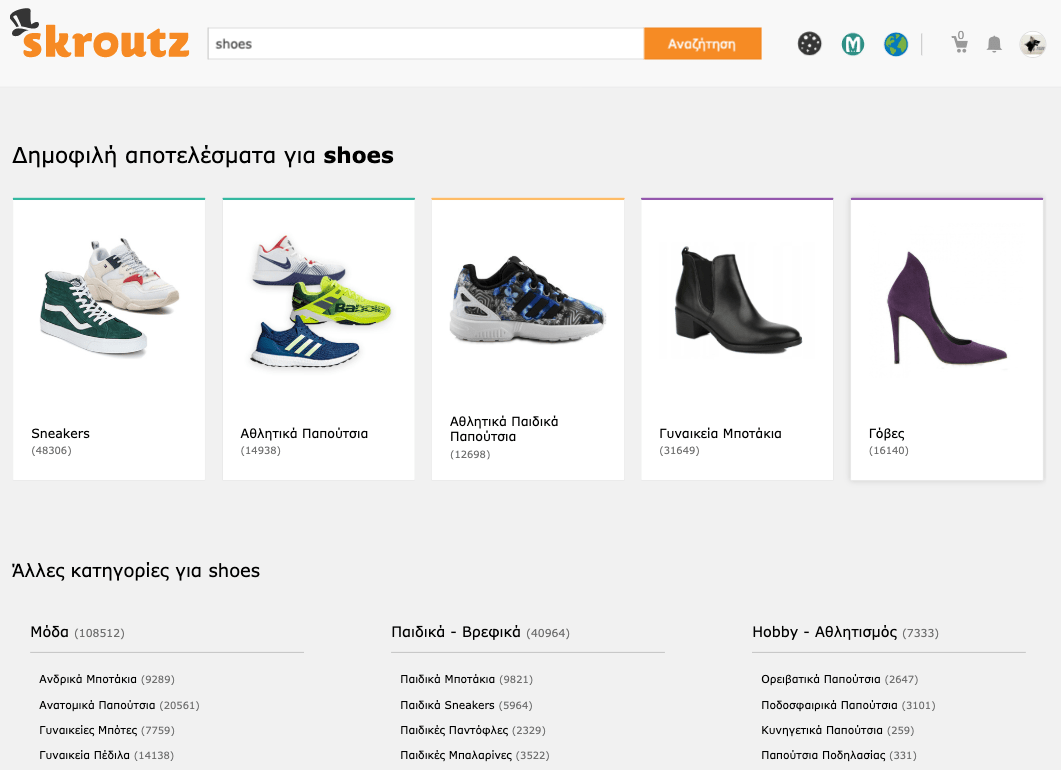
- 特点目录下的搜索结果: skroutz.gr/c/3363/sneakers.html?keyphrase=shoes
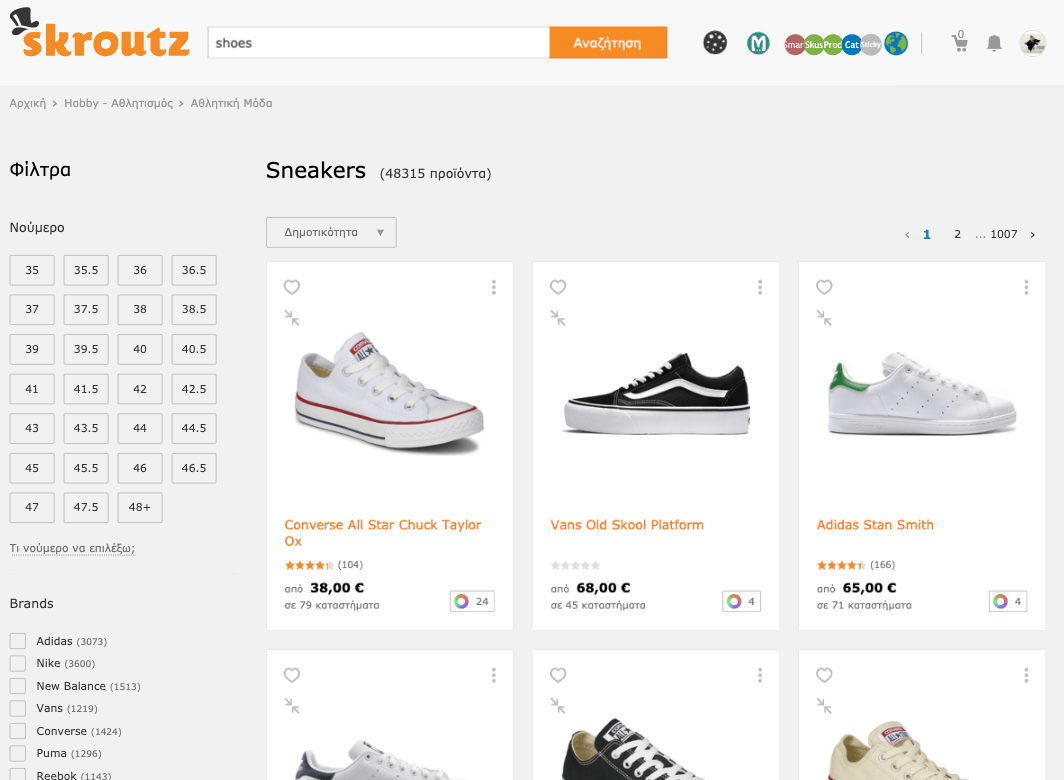
注意:无目录的搜索页面上,都有链接都指向目录搜索页面。 在我们的示例中,如果用户在skroutz.gr/search?keyphrase=shoes上并单击“ Sneakers”,则他将访问skroutz.gr/c/3363/sneakers.html?keyphrase=shoes这一页面。
这就是内部搜索页面的创建方式。 已索引的内部搜索页面中有95%是目录搜索页面。
现在很明显问题出在哪了…无目录搜索页面上有很多入口指向具有相同查询词的目录搜索页面。 有了这个漏洞,每个不同的搜索查询都可以创建数百个目录搜索页面。
这就是为什么skroutz.gr/search?keyphrase=v2会申城大量新的目录搜索页面,例如
- skroutz.gr/c/3363/sneakers.html?keyphrase=v2
- skroutz.gr/c/663/gamepads.html?keyphrase=v2
- skroutz.gr/c/1850/Gaming_Headsets.html?keyphrase=v2
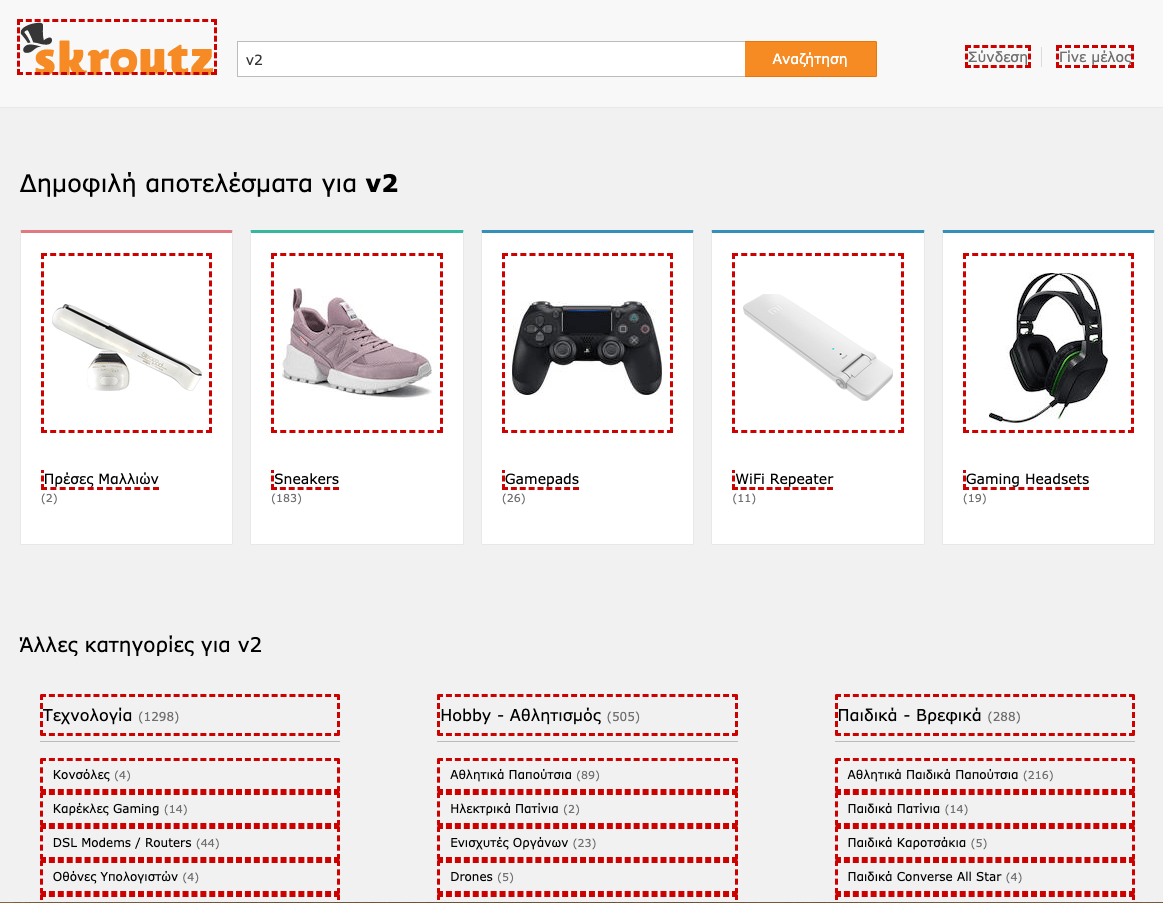
Googlebot可以访问上图中所有红色链接。 因此,每次访问无目录搜索页面时,它都会跟踪并抓取数百个新的目录搜索页面。
我们通过以下方式解决了此问题
1.给所有这些链接加上nofollow属性,除了一些有价值的,有效的关键词(之后会具体解释)
2.检查70,000个访问最多的内部搜索页面信息,并将其中20,000个直接重定向到目录页或目录搜索页中。 这样的话,Googlebot和用户都不会看到无目录搜索页面。
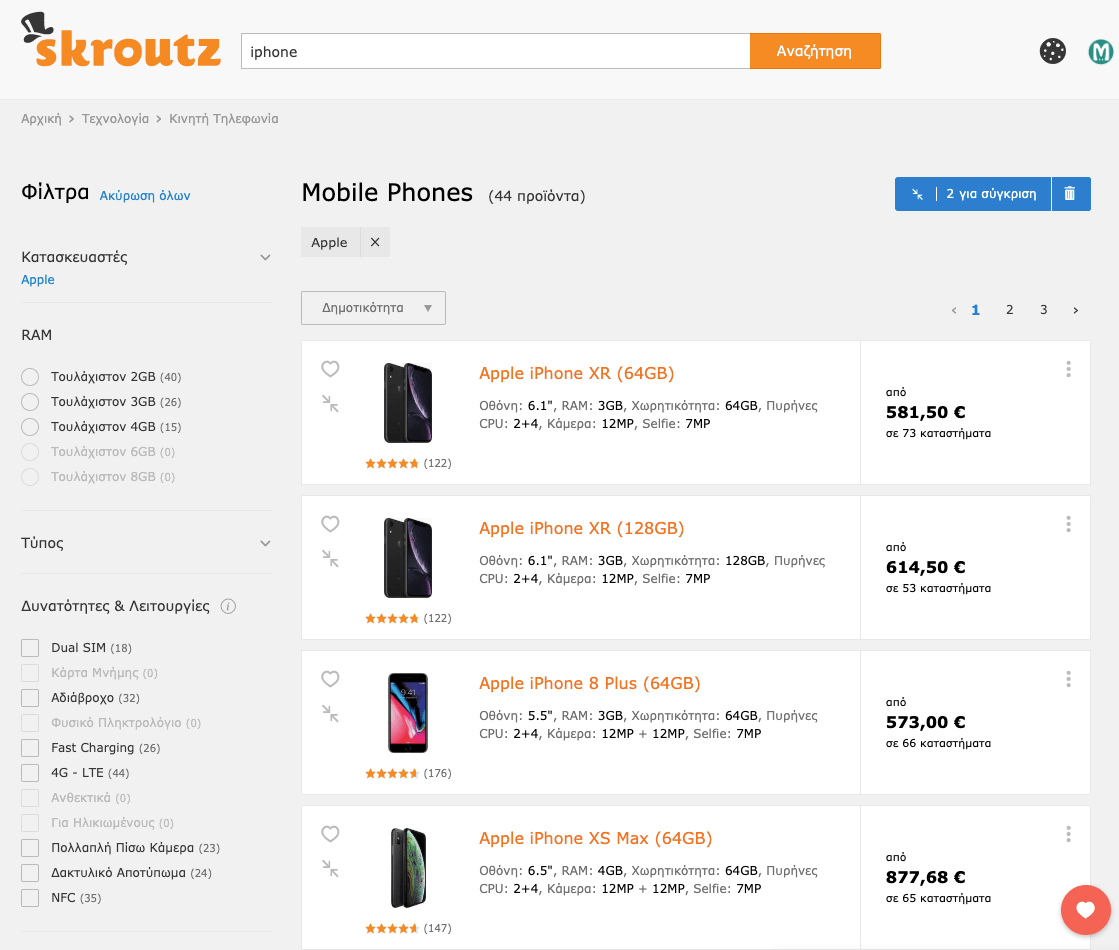
例如,我们发现在搜索iphone的用户中,> 95%的用户希望看到手机而不是任何配件。 因此,不要显示无目录搜索页面:
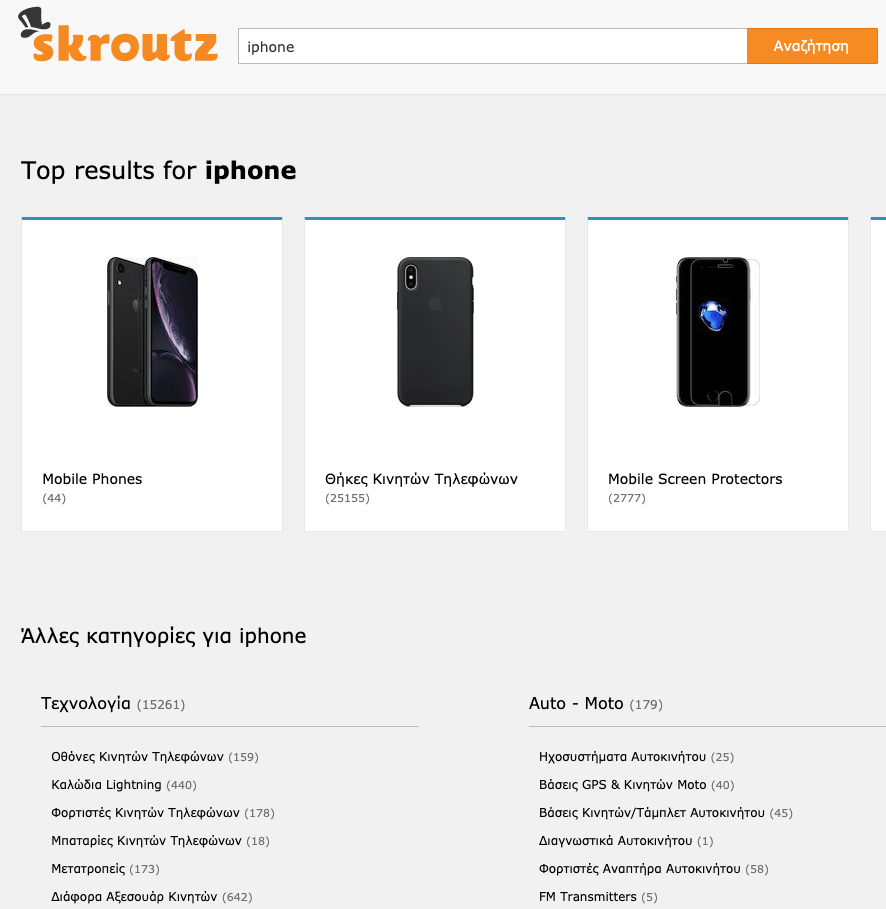
We redirect the user directly to a dedicated category search, based on their search intent:
我们根据用户的搜索意图将其直接重定向到专用的类别搜索:
2. 降低页面收录数量
解决了无目录搜索页面(如skroutz.gr/search?keyphrase=v2)的问题之后,之前提到该页面创建了越来越多的目录搜索页面,是时候干掉他们了。
目录搜索页面(例如skroutz.gr/c/3363/sneakers.html?keyphrase=v2)具有庞大的索引量。 因此,我们必须查看Googlebot抓取了多少个页面,其中哪些页面有被索引的价值。
这项任务花了我们一年多的时间(2018年2月至2019年6月)。 就小时数和劳动力而言,它既庞大又昂贵,但这是值得的。
对于此任务,我们决定创建一种机制,以使SEO团队无需开发人员即可合并我们的无索引页面。
但是,我们如何以及在哪里整合内部搜索页面?
那很简单! 我们发现,大多数目录内部搜索URL与现有目录页面几乎是重复的。 例:
- skroutz.gr/c/25/laptop.html?keyphrase=ultrabook (目录搜索页面)
- skroutz.gr/c/25/laptop/f/343297/Ultrabook.html (目录页面)
首先,我们创建了一个仪表板,其中包含每个类别的所有内部搜索关键字,并结合了访问量和抓取次数(我们将其称为“关键字管理”仪表板)。 正如我们之前所说,每个关键字短语可能出现在多个内部搜索URL上。
然后,我们添加了快速操作按钮,因此SEO团队最终可以在没有开发人员帮助的情况下执行以下操作:
- 跳转或合并
- noindex的标签添加
- 标注为有价值的内部搜索页面
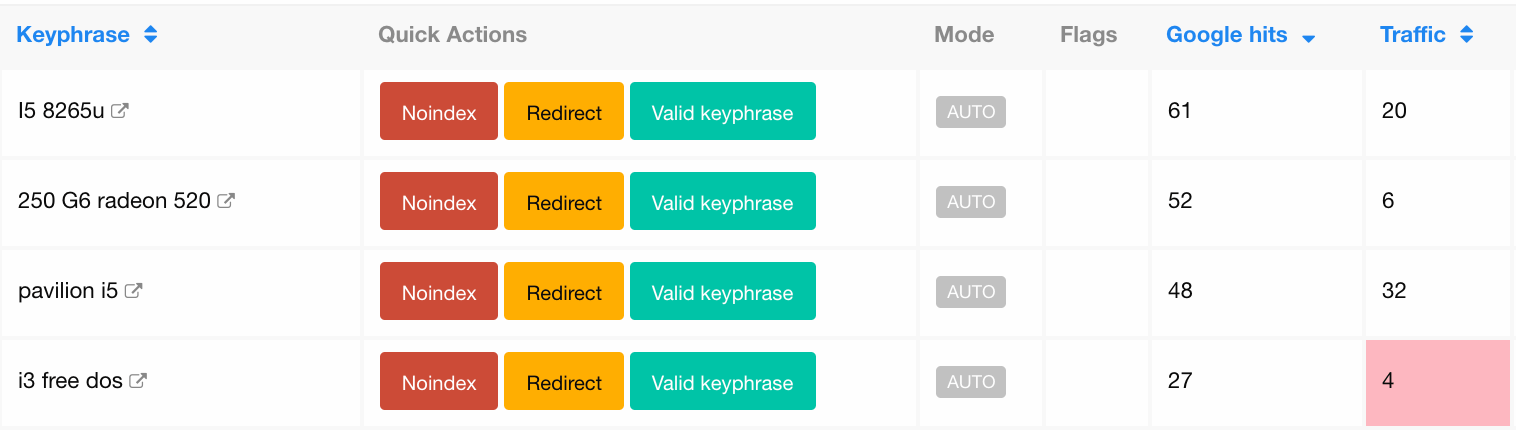
选择“重定向”操作时,将显示一个弹出窗口,以便他们可以选择重定向目标(最多2个条件筛选+ 1个制造商筛选)。
为什么我们按关键词而不是URL分组?
由于许多URL组合(筛选项+关键词)中都存在相同的关键词,因此我们为一个关键字短语执行的每项操作都可以对使用相同的关键字的数十个相似的URL生效,从而节省了我们的时间。
例如,假设我们在笔记本电脑类别中有以下两个内部搜索URL,其关键词为ultrabook:
- skroutz.gr/c/25/laptop.html?keyphrase=ultrabook (关键词)
- skroutz.gr/c/25/laptop/m/355/Asus.html?keyphrase=ultrabook (关键词+筛选条件)
对于这两个URL,仪表板都会向我们显示超级本作为关键短语,但是我们知道笔记本电脑类别中有一个针对超级本的选项
我们可以选择操作“重定向”,然后选择“ Ultrabook过滤器”作为重定向目标。 然后,该系统会将上面的URL分别重定向到以下URL:
- skroutz.gr/c/25/laptop/f/343297/Ultrabook.html
- skroutz.gr/c/25/laptop/m/355/Asus/f/343297/Ultrabook.html
The mechanism gathered an immense amount of keywords, reaching 2.7 millions in total! These 2.7Μ keyphrases where part of 14M indexed URLs (estimated).
该系统收集了大量的关键字,总计达到270万个关键字! 270万个关键词大约覆盖了1400万的索引URL。
此后,我们的团队开始从流量和抓取量方面最多的关键字开始手动配置这些关键字。 此外,我们的开发团队还提供了一些方便的自动化方法,例如将关键词与相同的产品结果分组在一起,并且只需一次操作即可将其全部处理。
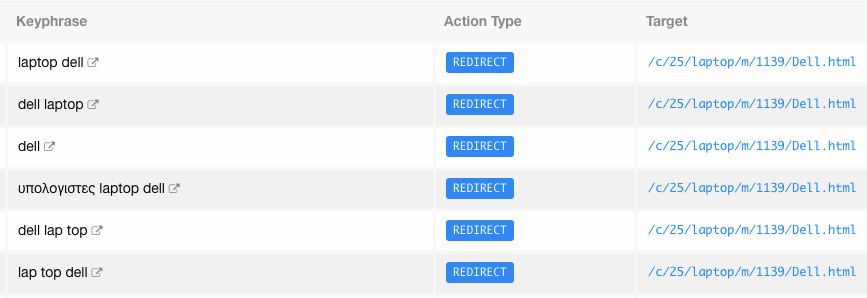
以上所有内部搜索关键字词组在“笔记本电脑类别”中具有相同数量的产品结果。 如您所见,它们都是关于戴尔笔记本电脑的。 因此,可以在Dell类别Filter中立即将它们重定向。
此步骤的操作有助于整理大约5%的总关键字。 索引大小在2018年7月从2500万减少到2100万,但这还不够。
除了我们的手动工作之外,我们还创建了一些自动化的脚本和机制来重定向内部搜索页面,并且几乎没有让它们被收录。 其中一些最重要的是:
- 无索引脚本:我们为所有专用类别搜索页面建立了不索引脚本
- 在过去两个月内没有访问
- 在过去6个月内没有访问且不超过3次抓取
- Redirect脚本:我们重定向了一个专用的类别搜索页面:
- 如果搜索(关键字)返回了该类别的所有产品,则返回到类别规范URL。 例如,“运动鞋”关键字的结果中,100%的产品属于“运动鞋”类别。 因此,skroutz.gr/c/3363/sneakers.html?keyphrase=sneakers被重定向到目录页)
- 使用分词脚本,将搜索页转换为特定的目录页URL。 例如,“ stan smith black”查询匹配两个不同的过滤器:“ Stan Smith”和“ Black”。 因此,如果用户搜索“ stan smith black”,他将在启用两个过滤器的情况下重定向到类别页面。
备注:在过去的几个月中,我们正在运行一种更复杂的机制,该机制将上述语言标识符脚本的某些智能与其他因素结合使用。 该机制可以分解每个搜索查询,将其关键字短语与现有筛选项匹配,然后将内部搜索网址重定向到特定的过滤器/筛选项组合网址。
该机制每天处理大量内部搜索查询次数:120,000(18%)
当SEO团队手动或自动完成所有工作后,我们迈出了最后一步,以整理内部搜索页面内的长尾页面。 我们为内容编辑创建了一个基本的SEO培训课程,其中包括workshop,1-1动手操作和Wiki指南。 这些成员反过来可以帮助我们执行上述价值。 SEO团队会一直在关注项目进度。
分享这些知识在许多方面极大地使我们受益。 例如,由于人力资源的优化,我们的内容团队可以更好地了解访问者正在搜索的内容,从而帮助他们创建了更有用的筛选条件。
总而言之,在经过近一年的手动和自动管理之后,我们最终整理了2,700,000个关键词,它们对应于大约14,000,000个URL!
具体来说,在270万搜索关键字中:
- 220万未编入索引(不要期望这些会立即从Google索引中删除。我们看到了一些延迟,从几天到几个月不等)
- 300,000被重定向到过滤器页面网址或目录页
- 200,000被标记为有效关键字
那是我们的主要项目。
在看到我们努力的结果之前,我们先简单地说下辅助SEO项目
二级SEO项目(优化合并/拆分类别和警报机制)
1. 合并/拆分类别时优化SEO
在处理主要项目(抓取预算)时,我们还为一些次要任务排进了日程。
第一个是在合并或拆分类别时优化和自动化我们的过程,以免丢失任何SEO权重并提供更好的用户体验。
- 合并类别是指将“婴儿洗发水”和“儿童洗发水”两个不同的类别合并为一个类别
- 划分类别是指将一个类别划分为两个或多个类别的过程。 例如,“夹克”类别可以分为女式夹克和男式夹克类别。
上面所有这些都会导致大量重定向,因此必须将SEO汁从旧URL“转移”到新URL。 为了优化整个过程,我们要做的是创建一个易于使用的合并/拆分工具,因此内容团队(负责产品)可以轻松地将旧URL与新URL映射。
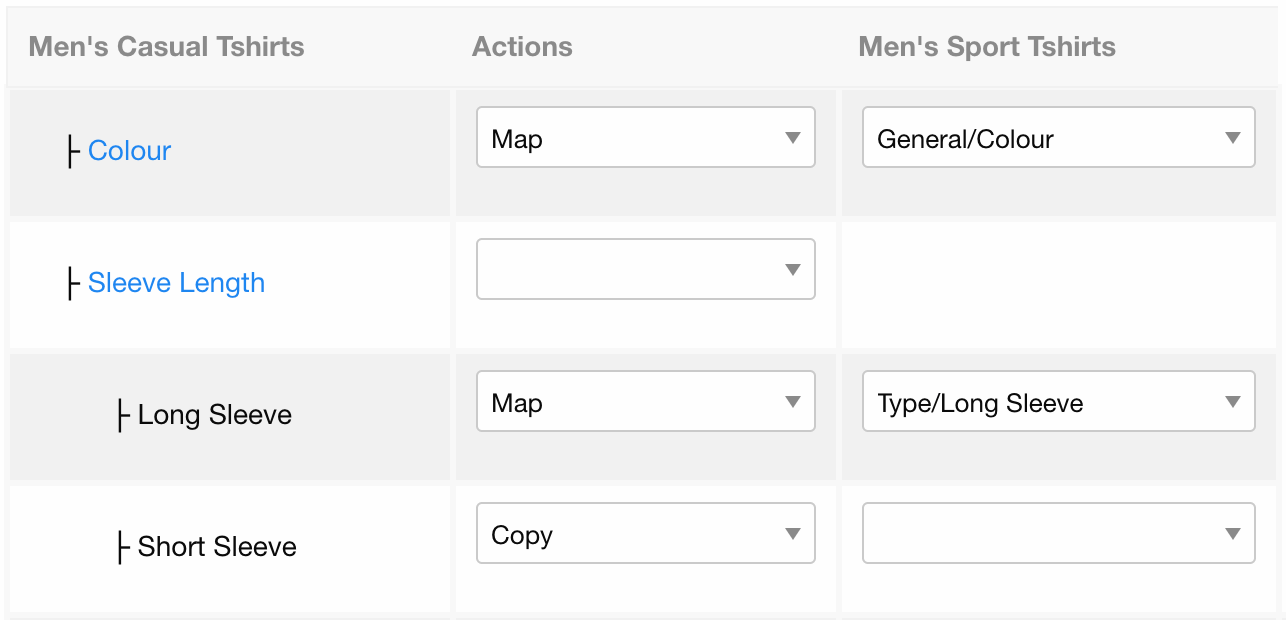
合并工具显示了这两个类别中的所有过滤器,因此内容团队可以对其进行映射或复制。 然后,该机制将使用此信息来自动进行重定向
2. 创建警报机制
除了关键短语管理,我们还建立了一种机制,当出现严重的爬虫抓取或索引问题时,该机制可以向SEO团队发送通知。
这种机制如何运作?
根据警报类型,该机制会在达到如下指标(数字)时发送警报:
- 超过特定阈值(例如20,000个404 未找到页面)
- 与过去30天的正常统计波动明显不同
至于我们使用的工具,我们已经在Grafana警报引擎中设置了警报规则,该规则被传递到Slack频道。
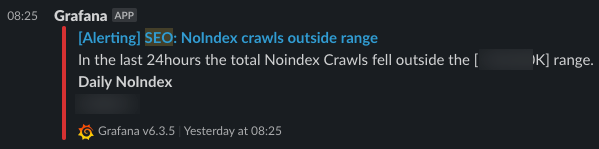
收到通知后,我们将使用Kibana监控工具来更深入地分析问题的根源。
Some examples of the alerts we have set:
我们设置的警报的一些示例:
- 网站地图的区别:在每天更新我们的网站地图文件之前,该机制会将每个生成的文件与已经提交的文件进行比较。 如果两者相差很大,警报机制会通知我们并立即阻止提交站点地图,直到我们验证数据为止
- Noindex抓取:如果Noindex页面的抓取超出指定的安全范围
- 找不到抓取:如果404页的抓取超出了指定的安全范围
- 重定向计数:如果启用了重定向的网页抓取超出了指定的安全范围
3: 效果复盘
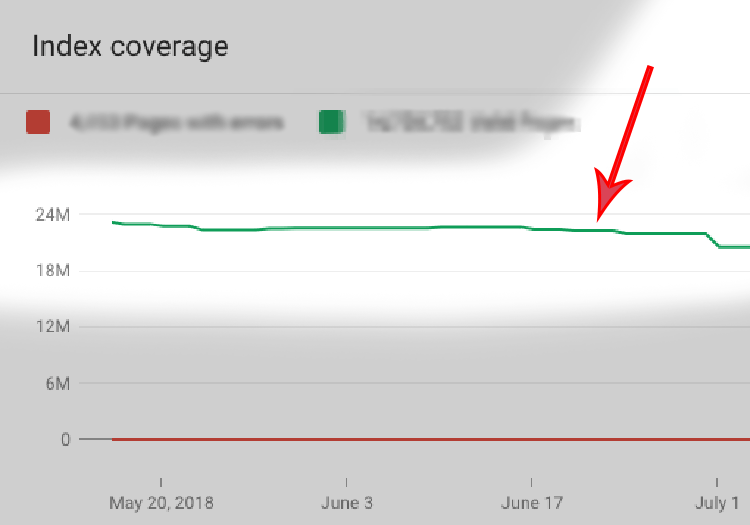
1. 收录数量优化
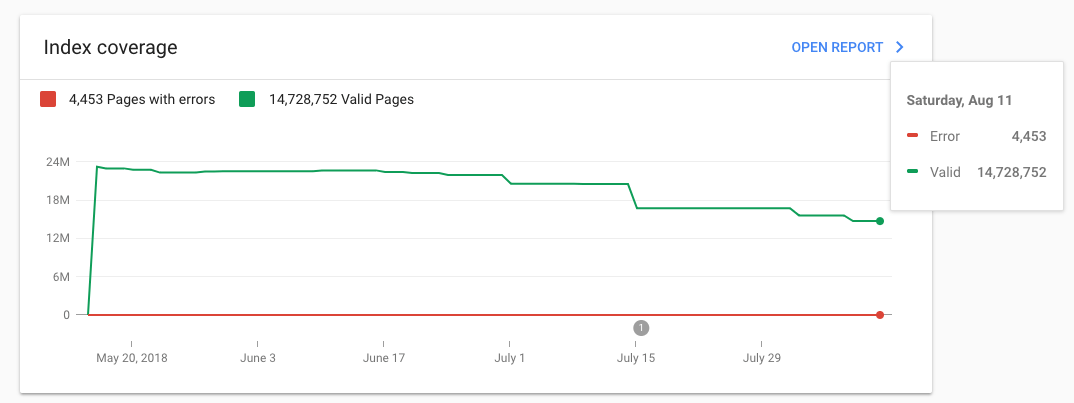
上图显示了经过七个月的辛勤工作和90%的关键短语被整理后的索引量变化。
现在,我们极大地缩小了实际索引页和预期索引页之间的距离,这意味着我们将大小从2500瓦减少到仅760万。
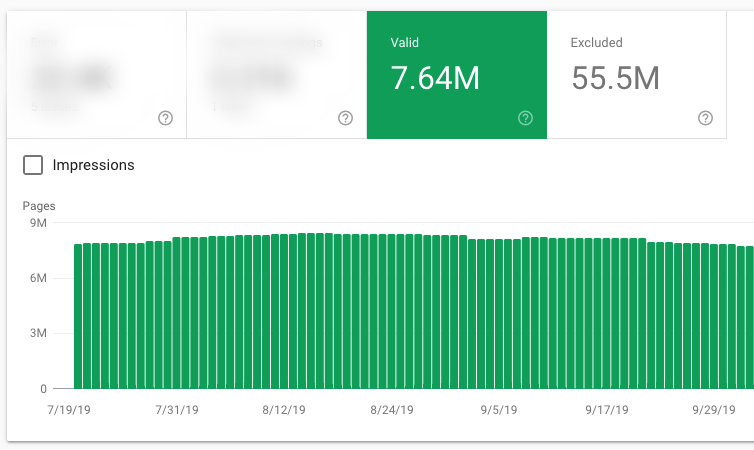
我们观察到的一件有趣的事情是:
即使您将URL标记为无索引,GoogleBot也不会立即停止对其进行爬网。 因此,如果您认为无索引标签会立即节省您的抓取预算,那您错了。
值得注意的是,我们发现在某些情况下,GoogleBot在2或3个月后返回,以抓取无索引页面。 我们为此创建了一些数据监控,我们发现:
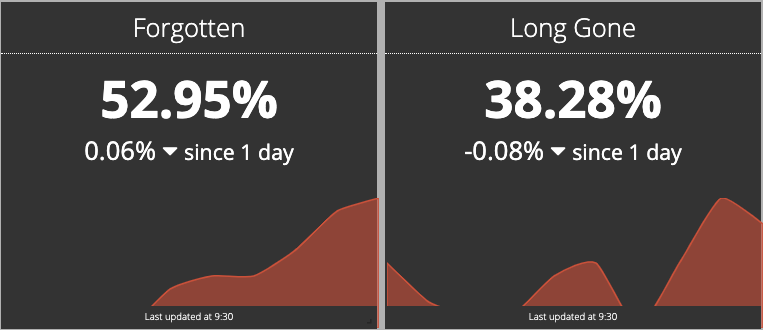
- Only half of our no-index internal search URLs haven’t been crawled for at least three months
- Only, 38.28% of our no-index internal search URLs haven’t been crawled for at least six months
- 我们至少有一半的no-index内部搜索URL至少三个月没有被抓取
- 有38.28%的no-index内部搜索URL的有六个月没有被抓取
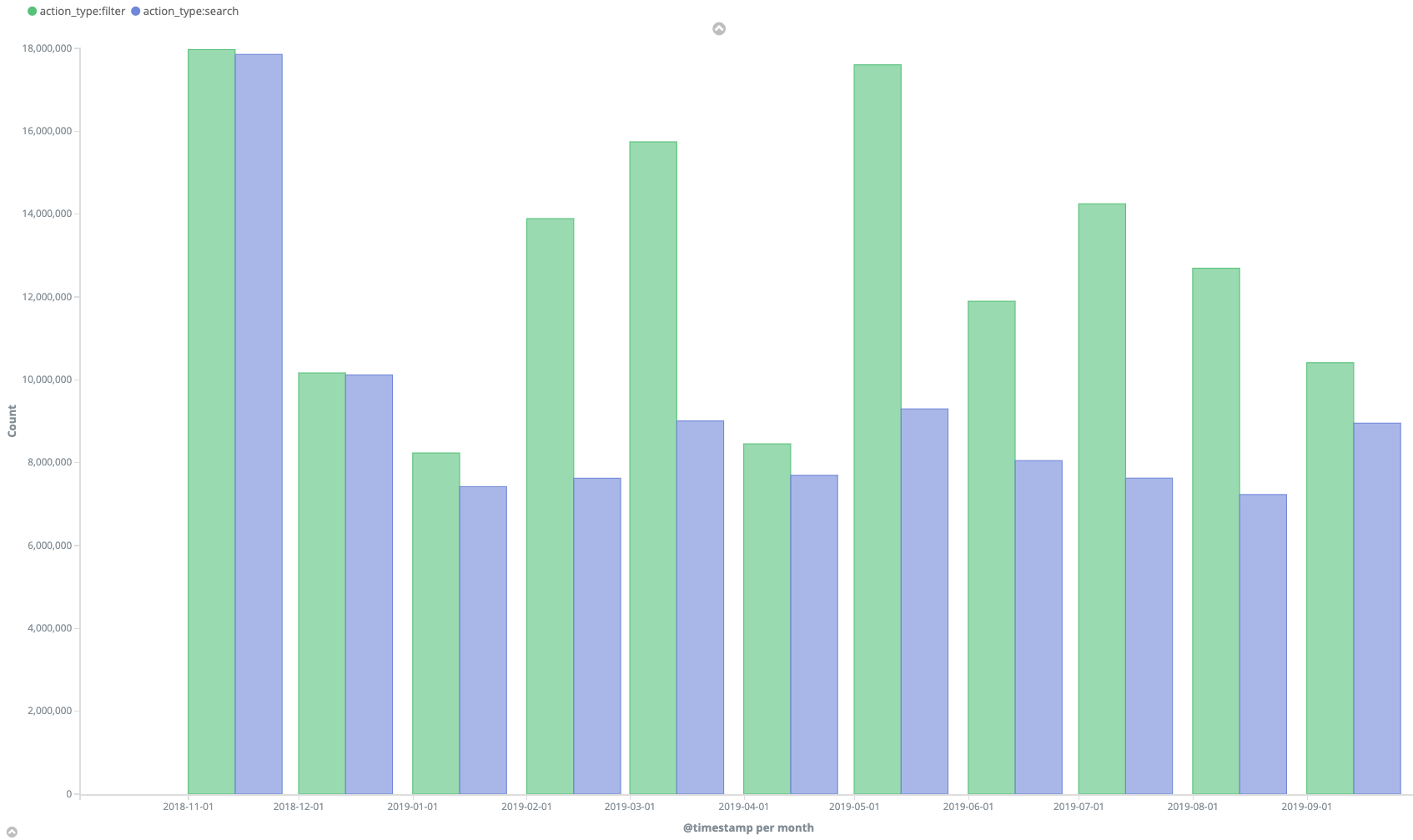
2. 提升条件筛选页面的抓取率
例如,以去年的内部搜索页面抓取(蓝色)与筛选页面抓取(绿色)的波动为例,很明显,我们迫使Googlebot相比内部搜索页面更频繁地抓取条件筛选页面。
3. 新URL被收录和排名的时间更短
就像我们在前面的示例中看到的那样,无需花2-3个月的时间对唯一的URL进行索引和排名,而索引和排名阶段现在只需几天。
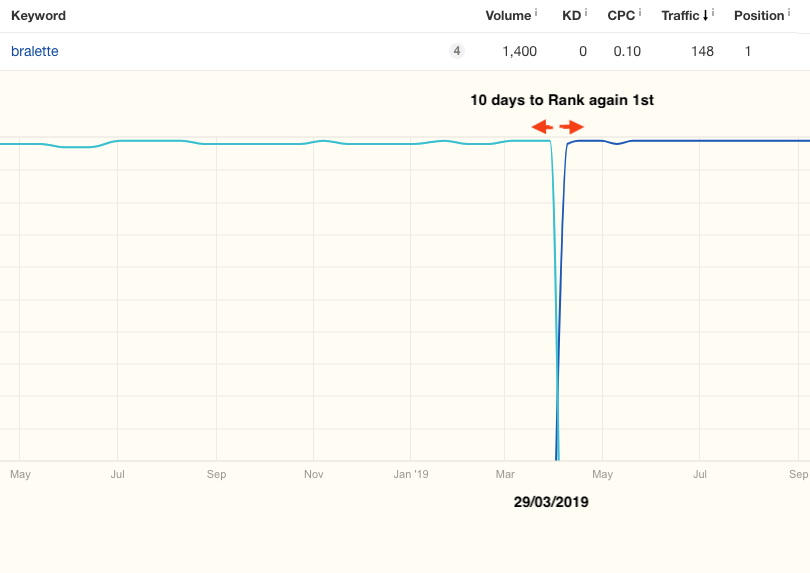
在29/03/2019,我们将内部搜索页面skroutz.gr/c/1487/Soutien.html?keyphrase=bralette重定向到了类别页面skroutz.gr/c/3361/Bralettes.html。
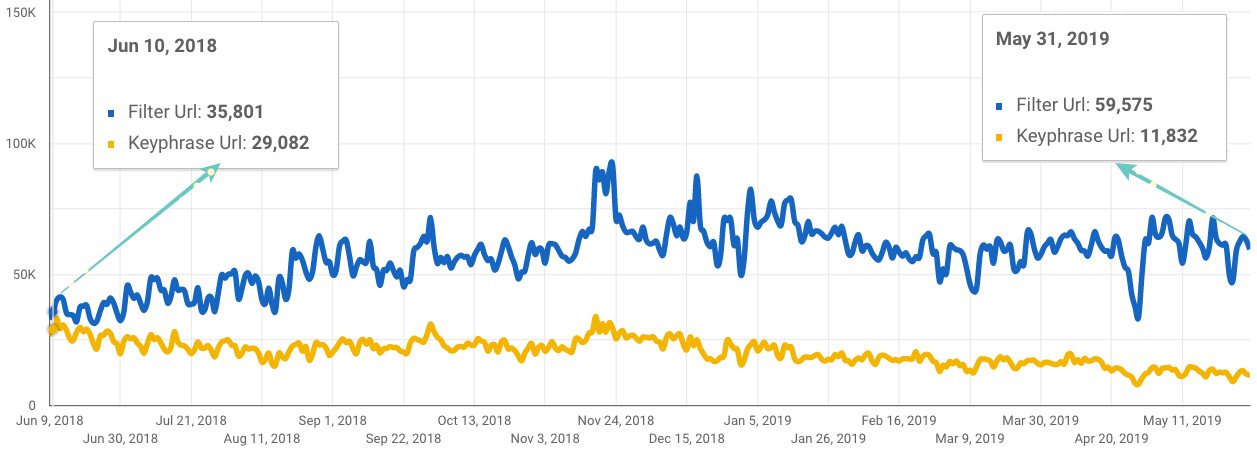
4. 筛选页面的流量得到明显提升
看看下面的Data Studio图表,其中包含2018年6月至2019年5月Search Console的数据(点击)。您可以看到与内部搜索关键字网址访问量相比,筛选页面URL的自然访问量是如何增加的,而内部搜索关键字短语的访问量则略有下降 。
5. 平均排名提升,展现量和点击量得到了提升
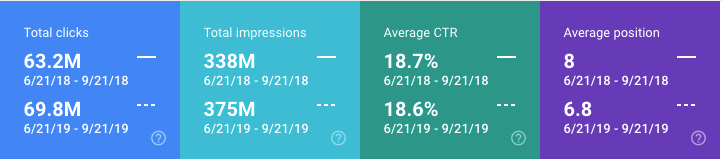
上述表格数据来源于 Google Search Console,我们将2018年夏季(恰好是我们启动SEO项目的时间)与2019年夏季进行了比较。
我们的Learning
在过去的两年中,我们在这个技术性SEO项目中学到了很多东西,我们希望分享一些可以为大家带来帮助的东西。
以下是我们学到的五个最重要的经验:
1:
对于大型站点,必须进行抓取量监视。 监控未必要实时。 您还可以每月或在网站进行重大更改后,使用诸如Screaming Frog或Sitebulb之类的网站搜寻器。 您会为这样做所带来的价值感到惊讶。
您可以从爬虫数据监控中获得启发,其中一个有趣示例是将类别列表产品页面切换到React时发现的一些关键问题。 在React部署后,GoogleBot开始像没有索引的疯狂的无索引页面一样进行爬网,尽管没有其他任何链接。 通过爬网监视,我们能够立即查看出现该问题的页面类型。
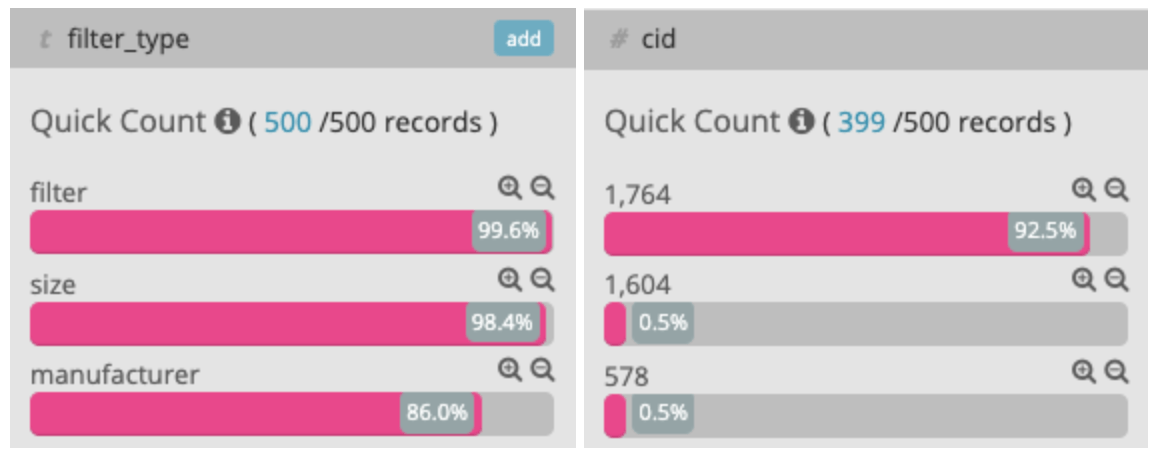
我们看到,大多数抓取都是在no-index的页面上进行的,在该页面上,ID为1764的类别的大小和制造商过滤器组合在一起
我们发现GoogleBot执行了内联<script />并将某些相对URL路径解释为常规URL,然后以较高的速度进行抓取。 我们通过在脚本中添加一个虚拟URL验证了这一假设,随后我们看到GoogleBot能够进行抓取。
2:
将页面更改为无索引后,Googlebot不会立即停止抓取。 可能需要一些时间。 我们发现没有索引的URL会被爬行几个月,然后才能从Google索引中删除。
3:
如果操作不正确,合并URL很容易适得其反。 重定向到另一个的每个URL必须彼此高度相关(内容几乎完全一样)。 我们已经看到,重定向到不相关的页面具有相反的结果。
4:
合并或拆分类别时,请始终注意。 我们发现,即使您保持排名稳定,也可能会延迟数月之久,您可能因此而失去很多点击。 将旧的URL映射到新的URL和301重定向确实有帮助。
5:
SEO不是单人表演,也不是单队表演。 分享SEO知识和与其他团队合作可以以多种方式增强整个组织的能力。 例如,Skroutz.gr的搜索团队通过建立我们在SEO项目中使用的工具和机制的大多数技术基础架构,进行了出色的工作。
最后,其他职能部门(例如内容团队和市场营销部)的反馈发现了多少SEO问题。 甚至Skroutz.gr的首席执行官本人也为我们遇到的技术问题(脚本等)提供了很多帮助。